1. Petites manipulations avec GAWK
Il arrive souvent qu'on doive réaliser des "petites manipulations de texte" comme par exemple inverser le nom et le prénom dans le fichier suivant nommé prenomNom1.txt :
Marie DURAND
Jane SMITH
Jean DUPONT
Pierre DUPUIS
Réaliser cette inversion en moins d'une minute avec GAWK.
Etendre à des informations noms et prénoms séparées par des points-virgules, comme dans le fichier prenomNom2.txt :
Marie ; DURAND
Jane K. ; SMITH
Jean Simon Daniel ; DUPONT
Pierre Henri ; DUPUIS
Au passage, comment produire une liste triée par nom quand on utilise le format "prénom suivi de nom" ?
GAWK est un [petit] langage de scripts conçu pour ce genre de problèmes. Le mot numéro 1 d'une ligne est $1, le mot 2 est $2 donc en gros print $2 " " $1 permet d'inverser les mots 1 et 2. Démonstration :
$gh> cat prenomNom1.txt
Marie DURAND
Jane SMITH
Jean DUPONT
Pierre DUPUIS
$gh> gawk -e ' { print $2 " " $1 } ' prenomNom1.txt
DURAND Marie
SMITH Jane
DUPONT Jean
DUPUIS Pierre
Si les informations noms et prénoms sont séparés par des points-virgules, comme dans le fichier prenomNom2.txt, il suffit de prévenir GAWK d'utiliser le point virgule comme séparateur, soit :
$gh> cat prenomNom2.txt
Marie ; DURAND
Jane K. ; SMITH
Jean Simon Daniel ; DUPONT
Pierre Henri ; DUPUIS
$gh> gawk -F ";" -e ' { print $2 " ; " $1 } ' prenomNom2.txt
DURAND ; Marie
SMITH ; Jane K.
DUPONT ; Jean Simon Daniel
DUPUIS ; Pierre Henri
Pour produire une liste triée par nom quand on utilise le format "prénom suivi de nom", il suffit de préciser à sort que le critère de tri est la clé (key en anglais, soit l'initiale k) numéro 2 :
$gh> cat prenomNom1.txt
Marie DURAND
Jane SMITH
Jean DUPONT
Pierre DUPUIS
$gh> sort -k 2 prenomNom1.txt # tri par NOM (mot 2)
Jean DUPONT
Pierre DUPUIS
Marie DURAND
Jane SMITH
2. Des exemples pas si simples que cela en LaTeX
Essayer de reproduire séparément en LaTeX les pages 3, 28, 61 et 64 du document rapm dont nous donnons des copies-écran ci-dessous (images cliquables).
 |
 |
| Page 3 |
Page 28 |
 |
 |
| Page 61 |
Page 64 |
Afin d'éviter la resaisie du contenu de ces pages, les fichiers page3.txt, page28.txt, page61.txt et page64.txt en contiennent le texte brut. On viendra recoder la page 3 en ASCII 7 bits donc sans aucun caractère accentué explicite, la page 28 en UTF-8 et les pages 61 et 64 en ISO8859-15 afin de comprendre comment on prévient LaTeX de ces encodages.
Pour la page 28, le tracé de la fonction est dans le fichier postscript encapsulé rapm03a.eps.
Après avoir consulté les quatre fichiers de l'archive rapm_pagsd.zip expliquer comment fonctionne la numérotation et l'affichage des exercices et de leurs solutions. Au passage, on pourra essayer de deviner comment l'image de la page 28 a été générée.
2.1 Reproduction de la page 3
Il n'y a pas beaucoup de difficultés à produire ce début de chapitre LaTeX. Il faut utiliser la classe book, sans doute utiliser a4paper pour avoir une dimension de page française. Il y a trois notations spéciales : les symboles pour l'ensemble N des entiers et pour l'ensemble R des réels et le symbole losange pour la fin d'énoncé d'exercice. On trouvera ci-dessous le code LaTeX correspondant nommé page3.tex.
\documentclass[a4paper,12pt]{book}
\def\N{\mbox{I\hspace{-0.11em}N}}
\def\R{\mbox{l\hspace{-0.11em}R}}
\def\fdd{\ensuremath{\diamondsuit}}
\begin{document}
\setcounter{page}{3}
\chapter[Ensembles et Fonctions]{Ensembles et Fonctions}
\section{Ensembles}
Les ensembles sont souvent le premier type de structure que l'on manipule
en math\'{e}matiques. Intuitivement, un ensemble est une "collection",
un "regroupement". Mais seule une d\'{e}finition abstraite que les math\'{e}maticiens
en donnent, via une axiomatisation rigoureuse aboutit \`{a} des paradoxes.
Ainsi, "un ensemble contient des \'{e}l\'{e}ments", "un ensemble ne peut pas
\^{e}tre un \'{e}l\'{e}ment de lui-m\^{e}me", mais qu'est-ce alors que l'ensemble dont les
\'{e}l\'{e}ments sont les ensembles qui ne se contiennent pas eux-m\^{e}mes ? Passer \`{a} ce
niveau de discours th\'{e}orique (ou rh\'{e}torique ?) est loin des calculs \'{e}l\'{e}mentaires que
nous proposons ici.
La notation $x\in E$ indique que $x$ est \'{e}l\'{e}ment de $E$.
Classiquement, les \'{e}l\'{e}ments sont d\'{e}sign\'{e}s par des lettres minuscules
et les ensembles par des majuscules. Pour indiquer que $E$ contient
les \'{e}l\'{e}ments $x$, $t$ et $u$ seulement, on borne la liste $x,t,u$
par des accolades, soit l'\'{e}criture $E=\{\ x,t,u\ \}$. L'ordre n'a aucune
importance et donc le $E$ cit\'{e} est aussi $\{\ x,u,t\ \}$.
En particulier, nous manipulerons beaucoup des ensembles de nombres
comme \N, \R\ et ce peut \^{e}tre une bonne habitude que d'ordonner les \'{e}l\'{e}ments des
ensembles consid\'{e}r\'{e}s.
\textbf{Exercice \thesection}
Un ensemble contient des
\'{e}l\'{e}ments distincts non ordonn\'{e}s. Donc
$\{ x,x \}$ et $\{ x \}$ d\'{e}signent le m\^{e}me ensemble.
De m\^{e}me : $\{ x,y \} = \{ y,x \}$. Mais combien
y a-t-il d'\'{e}l\'{e}ments dans l'ensemble $\{ x,y \}$ ?
\fdd
\end{document}
Après compilation de ce fichier, on obtient le fichier page3.pdf qui pour un oeil averti contient quelques différences avec la page originale.
Tout d'abord il y a marqué chapter et non pas chapitre. LaTeX est "francisable" mais il faut rajouter quelques instructions pour cela, comme par exemple \usepackage[french]{babel}. Pour plus de détails, voir notamment frenchb-doc. Ensuite, il manque un point juste après le chiffre 1 de chapitre 1, ce qui peut se faire en redéfinissant la commande \thechapter.
On pourra consulter le fichier rapm.sty utilisable via \usepackage{rapm} pour voir cette redéfinition.
Le deuxième paragraphe a un retrait de première ligne que n'a pas l'original, de même que l'intitulé de l'exercice et son énoncé, mais on pourra se contenter de cette version presque identique à celle proposée.
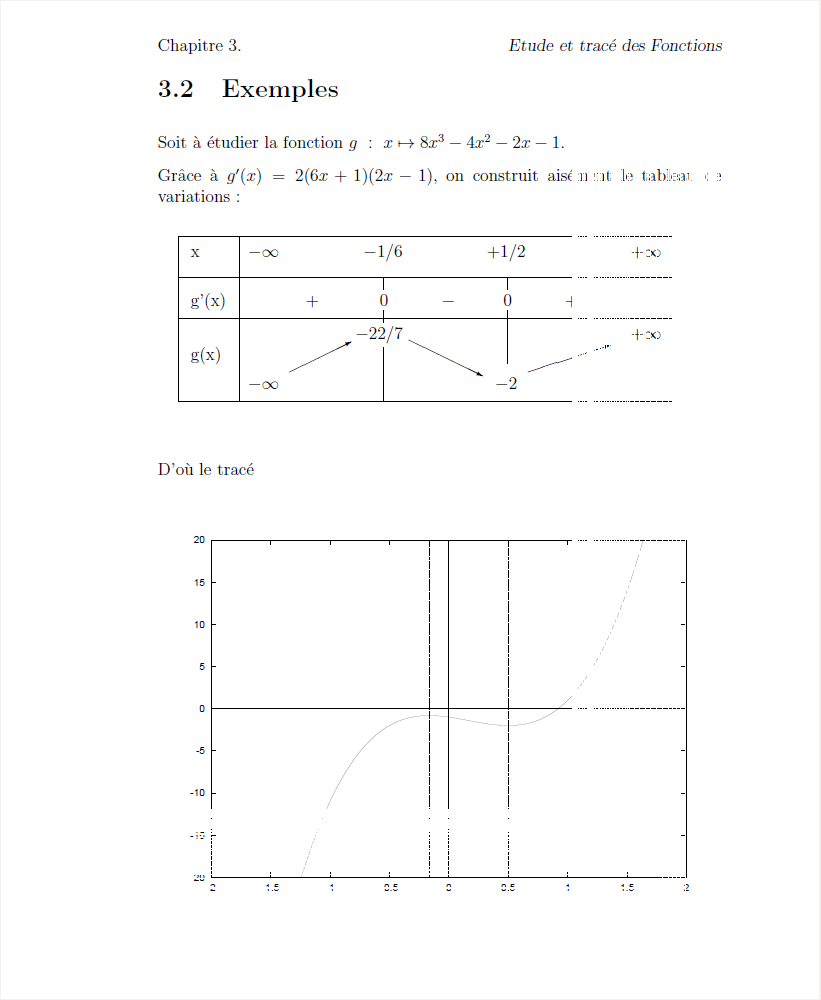
2.2 Reproduction de la page 28
Si on excepte le haut de page qui reprend le numéro et le titre du chapitre, il y a une seule difficulté dans cette page, à savoir le tableau de variations puisque le tracé de la fonction est fourni dans le fichier rapm03a.eps.
Pour ce tableau de variations, une solution simple mais un peu longue consiste à définir une figure pour LaTeX ou plutot à utiliser un environnement picture. On commence en générall par ébaucher à l'aide d'un papier et d'un crayon le tableau de variations et en déduire des coordonnées approximatives de tracé qu'on reprend ensuite sous LaTeX avec les instructions \put, \line et \vector.
On trouvera ci-dessous le code LaTeX correspondant nommé page28.tex. Le rendu est dans le fichier page28.pdf.
\documentclass[a4paper,12pt]{book}
\usepackage[utf8]{inputenc}
\usepackage[dvips]{graphicx}
\begin{document}
\setcounter{page}{28}
\setcounter{chapter}{3}
\setcounter{section}{1}
\section{Exemples}
Soit à étudier la fonction $g\ :\ x\mapsto 8x^3-4x^2-2x-1$.
Grâce à $g'(x)=2(6x+1)(2x-1)$, on construit aisément le tableau de variations~:
\unitlength=1mm
\begin{picture}(100,55)
%
\put(05,50){\line(1,0){120}} \put(08,45){x} \put(22,45){$-\infty$} \put(50,45){$-1/6$}
\put(80,45){$+1/2$} \put(115,45){$+\infty$}
%
\put(05,40){\line(1,0){120}} \put(08,33){g'(x)} \put(36,33){$+$}
\put(54,33){$0$} \put(69,33){$-$} \put(84,33){$0$}
\put(99,33){$+$}
%
\put(05,30){\line(1,0){120}} \put(22,13){$-\infty$}
\put(48,25){$-22/7$} \put(82,13){$-2$}
\put(115,25){$+\infty$} \put(08,20){g(x)}
%
\put(05,10){\line(1,0){120}} \put(05,10){\line(0,1){40}}
\put(020,10){\line(0,1){40}} \put(125,10){\line(0,1){40}}
\put(55,10){\line(0,1){13}}% pour 22/7
\put(55,29){\line(0,1){03}} \put(55,37){\line(0,1){03}}
\put(85,19){\line(0,1){13}} \put(85,37){\line(0,1){03}}
\put(32,17){\vector(2,1){15}} \put(90,17){\vector(3,1){20}}
\put(61,25){\vector(2,-1){18}}
\end{picture}
D'où le tracé
\begin{center}%
%\input rapm03a.tex
\rotatebox{270}{\includegraphics*[width=9cm]{rapm03a.eps}}
\end{center}
\end{document}
2.3 Reproduction de la page 61
On trouvera ci-dessous le code LaTeX correspondant nommé page61.tex. Le rendu est dans le fichier page61.pdf.
2.4 Reproduction de la page 64
On trouvera ci-dessous le code LaTeX correspondant nommé page64.tex. Le rendu est dans le fichier page64.pdf.
2.5 Numérotation et affichage des exercices et de leurs solutions
La numérotation et l'affichage des exercices et de leurs solutions sont assurés par des macros LaTEX.
Les voici, extraites des fichiers de l'archive rapm_pagsd.zip
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\usepackage{ifthen}
\def\fdd{\ensuremath{\diamondsuit}}
\newcounter{numexo}
\newcounter{numchp}
\newcounter{modsol}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\newcommand{\exo}{%
\addtocounter{numexo}{1}
\textbf{Exercice \thenumchp{}.\thenumexo}
\input rapmexo.tex
\fdd
}% fin de exo
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\ifthenelse{\equal{\thenumchp}{1}}{
%%
%% chap 1 exo 1 %
%%
\ifnum\thenumexo=1{
Un ensemble contient des
\'{e}l\'{e}ments distincts non ordonn\'{e}s. Donc
$\{ x,x \}$ et $\{ x \}$ d\'{e}signent le m\^{e}me ensemble.
De m\^{e}me : $\{ x,y \} = \{ y,x \}$. Mais combien
y a-t-il d'\'{e}l\'{e}ments dans l'ensemble $\{ x,y \}$ ?
% solution
\ifnum\themodsol=1{
\sol
Si $x$ est diff\'{e}rent de $y$ (ce qu'on pourrait croire avec
une telle \'{e}criture), il y a deux \'{e}l\'{e}ments dans $\{ x,y \}$
Sinon, il n'y en a qu'un.
}\fi % solution %
}\fi % \'{e}nonc\'{e} %
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
2.6 Génération de la figure pour la page 28
L'image est générée via le script suivant pour gnuplot dont une documentation en français est ici.
set terminal postscript landscape
set output "rapm03a.eps"
set sample 1500
## pour une petite taille : set size 1/2.,4/6.
set size 1
set nokey
set xrange [-2:2]
set yrange [-20:20]
f(x) = 8.0*x**3 - 4.0*x**2 -2*x -1
g(x) = 0
plot f(x) with lines, g(x) with lines, "rapm03a.ax1" with lines, "rapm03a.ax2" with lines
Les deux fichiers externes pour les axes, nommés respectivement rapm03a.ax1 et rapm03a.ax2 sont affichés ci-dessous :
0 -20
0 20
-0.166666667 -20
-0.166666667 20
0.5 -20
0.5 20
3. Un tracé de courbe en gnuplot+LaTeX ou R via PHP
Ecrire une page Web en PHP qui demande la définition d'une fonction, la plage de variations de x puis qui produit un PDF de la courbe de la fonction via gnuplot et LaTeX et un PNG de la courbe de la fonction via R.
Y a-t-il un intérêt à générer une figure LaTeX via gnuplot plutôt qu'un fichier eps ?
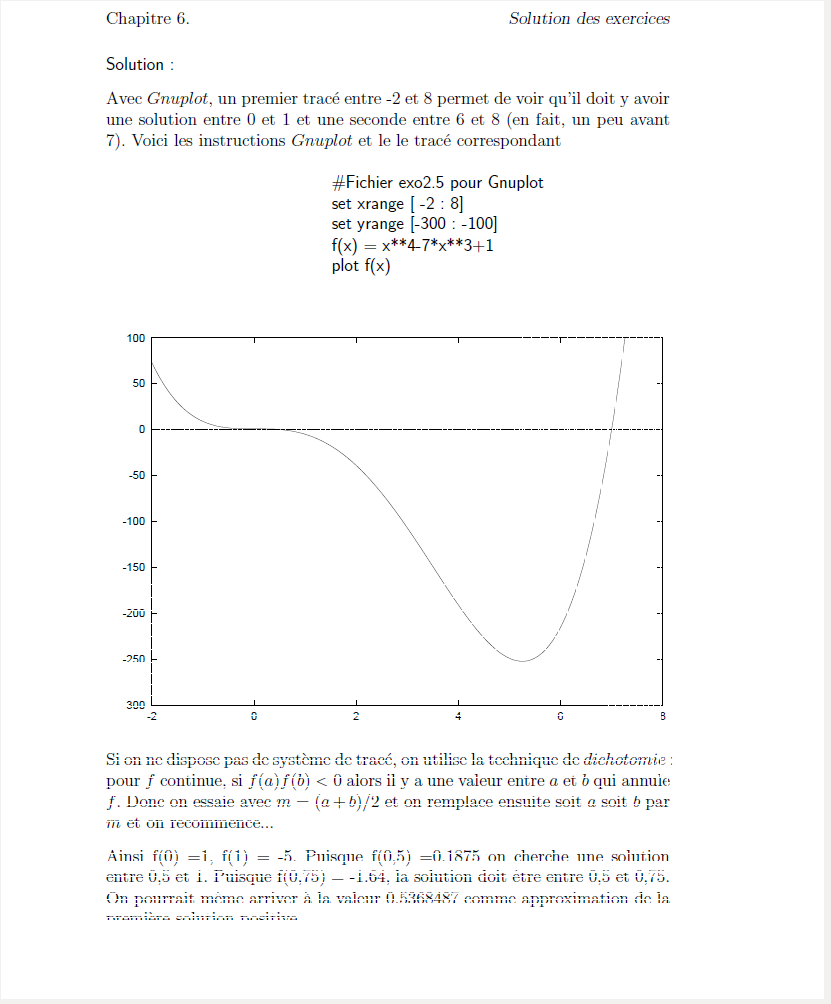
Hélas, à ce jour (2016), aucun étudiant ni aucun internaute averti n'a fourni de solution satisfaisante.
Toutefois on pourra lire le document LatexPourProfMaths (copie locale) et consulter les sites de PstPlus et PdfAdd.
Afin de tester Gnuplot, on pourra utiliser le script pag_01.gpl qui affiche à l'écran, le script pag_02.gpl qui produit un fichier Postscript encapsulé et le script pag_03.gpl qui produit le fichier LATEX pagsd03.tex.
Voici le premier script pour Gnuplot :
set sample 1500
## pour une petite taille : set size 1/2.,4/6.
set size 1
set nokey
set xrange [-2:2]
set yrange [-20:20]
f(x) = 8.0*x**3 - 4.0*x**2 -2*x -1
g(x) = 0
plot f(x) with lines, g(x) with lines, "rapm03a.ax1" with lines, "rapm03a.ax2" with lines
pause -1
Contenu du second script :
set terminal postscript landscape
set output "rapm03a.eps"
set sample 1500
## pour une petite taille : set size 1/2.,4/6.
set size 1
set nokey
set xrange [-2:2]
set yrange [-20:20]
f(x) = 8.0*x**3 - 4.0*x**2 -2*x -1
g(x) = 0
plot f(x) with lines, g(x) with lines, "rapm03a.ax1" with lines, "rapm03a.ax2" with lines
Contenu du troisième script :
set terminal latex
set output "pagsd03.tex"
set sample 1500
## pour une petite taille : set size 1/2.,4/6.
set size 1
set nokey
set xrange [-2:2]
set yrange [-20:20]
f(x) = 8.0*x**3 - 4.0*x**2 -2*x -1
g(x) = 0
plot f(x) with lines, g(x) with lines, "rapm03a.ax1" with lines, "rapm03a.ax2" with lines
4. Un graphe multi-états en LaTeX
Ecrire un document LaTeX qui produit la page suivante :
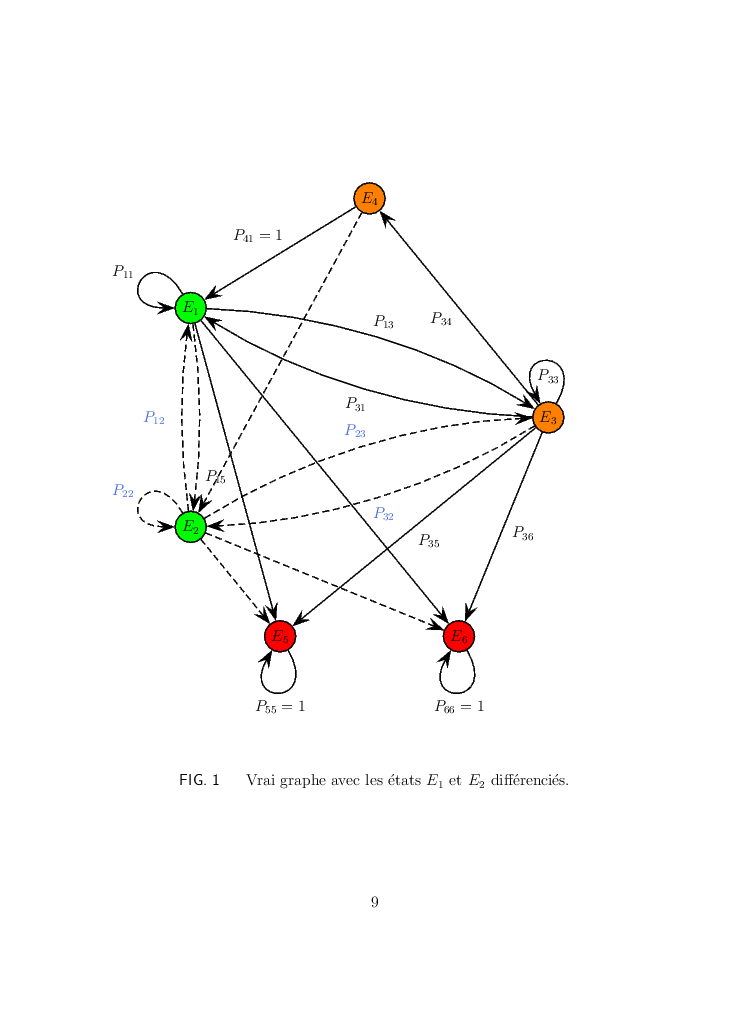
On utilisera PSTricks. On notera qu'il s'agit de la page numéro 9. Le PDF associé est nommé page9.pdf.
Voici le code LaTeX. Le fichier-solution se nomme graphe.tex.
% # (gH) -_- graphe.tex ; TimeStamp (unix) : 06 Août 2014 vers 15:48
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% %
% %
% DOCUMENT STANDARD %
% %
% %
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\documentclass[12pt,a4paper]{article}
%%%%%%%%%%%%%%%%%%%%%%% pour bien g\'{e}rer les accents sais tels quels
\usepackage[latin1]{inputenc}
%%%%%%%%%%%%%%%%%%%%%%% s'il y a besoin d'ins\'{e}rer des graphiques
\usepackage[dvips]{graphicx}
%%%%%%%%%%%%%%%%%%%%%%% si on \'{e}crit de smaths avec leqslant
\usepackage{amssymb}
%%%%%%%%%%%%%%%%%%%%%%% pour inclure des fichiers texte via \verbatiminput{ f }
%%%%%%%%%%%%%%%%%%%%%%% au lieu de \input f
\usepackage{verbatim}
\usepackage[french]{babel}
\usepackage{setspace}
%%%%%%%%%%%%%%%%%%%%%%%
\usepackage{color}
%\usepackage{bbold}
\usepackage{amssymb}
\usepackage{latexsym}
\usepackage{graphicx}
\usepackage{multicol}
\usepackage{pstricks}
\usepackage{eurosym}
\usepackage{geometry}
\usepackage{fancyhdr}
\usepackage{pstricks,pst-node,pst-text,pst-3d,pst-tree}
%%%%%%%%%%%%%%%%%%%%%%% j'aime bien avoir un point apr\`{e}s le num\'{e}ro de section
\renewcommand{\thesection}{\arabic{section}. }
\renewcommand{\thesubsection}{\arabic{section}.\arabic{subsection}}
\newrgbcolor{royalblue}{0.25 0.41 0.88}
%%%%%%%%%%%%%%%%%%%%%%% pour commenter facilement tout un block
\newcommand{\cmt}[1]{}
\parindent 2.0cm
\parskip 0.5cm
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\begin{document}
\setcounter{page}{9}
\begin{figure}
\begin{center}
\vspace{10mm}
\psset{arrows=->,mnode=circle}
\psset{arrowscale=3}
\begin{psmatrix}
& &[name=E4,fillstyle=solid,fillcolor=orange]$E_4$ \\[0.5cm]
[name=E1,fillstyle=solid,fillcolor=green]$E_1$
\\[0.5cm]
& & & & [name=E3,fillstyle=solid,fillcolor=orange]$E_3$
\\[0.5cm]
[name=E2,fillstyle=solid,fillcolor=green]$E_2$
\nccurve[angleA=120,angleB=180,ncurv=8,linestyle=dashed]{E2}{E2}\Bput{{\royalblue $P_{22}$}}
\ncarc[linestyle=dashed]{E1}{E2}\Bput{\hspace{-2cm}{\royalblue $P_{12}$}}
%\ncarc[linestyle=dashed]{E2}{E1}\Bput{~ ~ {\royalblue $P_{21}$}}
\ncarc[linestyle=dashed]{E2}{E1}
\ncarc[arcangle=15,linestyle=dashed]{E2}{E3}\Aput{{\royalblue $P_{23}$}}
\ncarc[arcangle=15,linestyle=dashed]{E3}{E2}\Aput{{\royalblue $P_{32}$}}
\ncline[linestyle=dashed]{E4}{E2}
\\[0.5cm]
& [name=E5,fillstyle=solid,fillcolor=red]$E_5$ & & [name=E6,fillstyle=solid,fillcolor=red]$E_6$
\nccurve[angleA=120,angleB=180,ncurv=8]{E1}{E1}\Bput{$P_{11}$}
\ncarc[arcangle=15]{E1}{E3}\Aput{$P_{13}$}
\ncarc[arcangle=15]{E3}{E1}\Aput{$P_{31}$}
\ncline{E4}{E1}\Bput{$P_{41}=1$}
\ncline{E1}{E5}\Bput{$P_{15}$}
\ncline{E1}{E6}
\ncline{E3}{E5}\Aput{$P_{35}$}
\ncline{E3}{E4}\Aput{$P_{34}$}
\ncline{E3}{E6}\Aput{$P_{36}$}
\nccurve[angleA=60,angleB=120,ncurv=8]{E3}{E3}\Aput{$P_{33}$}
\nccurve[angleA=-60,angleB=-120,ncurv=8]{E5}{E5}\Aput{$P_{55} = 1$}
\nccurve[angleA=-60,angleB=-120,ncurv=8]{E6}{E6}\Aput{$P_{66}=1$}
\ncline[linestyle=dashed]{E2}{E5}
\ncline[linestyle=dashed]{E2}{E6}
\\[0.5cm]
\end{psmatrix}
\vspace{15mm}
~
\textsf{FIG. 1} ~ ~ Vrai graphe avec les \'{e}tats $E_1$ et $E_2$ diff\'{e}renci\'{e}s.
\end{center}
\end{figure}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\end{document}
5. Affichettes triangulaires de présentation en LaTeX pour le Web
Une affichette triangulaire de présentation est une feuille de papier A4 imprimée des deux cotés avec le nom et le prénom d'une personne afin que tout le monde puisse voir son nom, que ce soit les personnes en face ou les personnes à coté. Images de démonstration :
 
Ecrire un document LaTeX pour réaliser une telle affichette. On pourra utiliser le fichier affichette.pdf comme modèle de document à produire. Ecrire ensuite un programme PHP en CLI qui demande un nom, un prénom et qui produit ensuite l'affichette correspondante au format PDF.
Ecrire enfin une page Web qui utilise un formulaire pour saisir des noms et des prénoms (séparés par des points-virgules), à raison d'une personne par ligne et qui produit un fichier PDF avec toutes les affichettes. On pourra réaliser une version "classique" avant de passer à une solution AJAX.
Méthodologie de développement
Comme il y a plusieurs difficultés dans cet exercice, il est sans doute bon de réfléchir à la méthodologie de développement à utiliser. On arrivera à se convaincre qu'il est "raisonnable" de :
-
commencer par mettre au point une page LaTeX "fixe", par exemple avec le nom Jean DUPOND ou John SMITH, histoire de régler les problèmes de taille de texte sur la largeur, de grande police de caractères, de retournement de texte ;
-
d'enchainer avec une macro ou une commande LaTeX, qui, à partir du nom et du prénom correctement écrits (nom en majuscules, notamment) vient tout afficher proprement et effectuer un saut de page ;
-
d'écrire ensuite un script PHP qui à partir d'un fichier texte avec un nom et prénom par ligne, produit tout le document LaTeX, avec le bon formatage au passege du nom et du prénom ;
-
de finir en CLI par un script qui exécute le PHP sur le fichier d'entrée, compile via LaTeX ou, en mode WEB, qui récupère les données via un formulaire, construit le fichier LaTeX, compile et met le fichier PDF résultat à disposition.
En effet, pour produire l'affichette, il faut être capable de
-
produire un texte en grand ;
-
savoir le retourner ;
-
sauter exactement 5 cm et écrire des pointillés.
Tout ceci n'est pas vraiment un problème pour LaTeX, comme le montre le code-source suivant :
\documentclass[12pt,a4paper]{article}
%
\usepackage[french]{babel}
\usepackage[T1]{fontenc}
\usepackage[latin1]{inputenc}
\usepackage[dvips]{graphicx}
\usepackage{geometry}
\usepackage{color}
\geometry{vmargin=3cm}
\newcommand{\cmt}[1]{}
\parindent 0.0cm
\parskip 0.0cm
%
\newcommand{\affichette}[1]{
\thispagestyle{empty}
\begin{center}
\makebox[\linewidth]{\dotfill}\\[5cm]
\rotatebox[origin=c]{180}{\resizebox{\linewidth}{1.5cm}{#1}}\\[9cm]
\resizebox{\linewidth}{1.5cm}{#1}\\[5cm]
\makebox[\linewidth]{\dotfill}
\end{center}
\newpage
}
%
\begin{document}
\thispagestyle{empty}
\affichette{Jean DUPONT}
\end{document}
Dans la mesure où le code précédent définit une macro \affichette, tout ce que le programme PHP doit accomplir pour produire une affichette se réduit à recopier tout le code jusqu'à \thispagestyle{empty} puis à insérer le bon appel de cette macro avant de terminer le fichier LaTeX, soit le code PHP :
<?php
## (gH) -_- affichette.php ; TimeStamp (unix) : 23 Février 2016 vers 15:18
##
## production d'une affichette de présentation triangulaire en LaTeX via PHP
##
error_reporting(E_ALL | E_NOTICE | E_STRICT ) ;
# 1. test des paramètres et aide éventuelle
if ($argc<2) {
echo "\n" ;
echo " Désolé, mais je n'ai pas assez d'informations pour produire l'affichette.\n" ;
echo " Vous devez fournir au minimum un mot, mais le mieux est de donner deux mots, \n" ;
echo " le premier correspondant au prénom et le second au nom de la personne.\n\n" ;
echo " En cas de prénoms ou noms multiples, utiliser des guillemets et séparer les prénoms des noms par un point virgule.\n\n" ;
echo " Syntaxe : php affichette.php Prenom NOM \n\n" ;
echo " Exemples : php affichette.php Jean DUPOND \n" ;
echo " php affichette.php \"Jean Marie ; DUPOND DURAND\"\n\n" ;
exit(-1) ; # force à quitter le programme
} # fin si
# 2. initialisation es variables
$pre = "" ;
$nom = "" ;
if ($argc==3) { $pre = $argv[1] ;
$nom = $argv[2] ;
} ; # fin si
if ($argc==2) {
$argv[0] = "" ;
$tabSplit = preg_split("/;/",join(" ",$argv)) ;
if (count($tabSplit)==1) {
$nom = $tabSplit[0] ;
} else {
$pre = $tabSplit[0] ;
$nom = $tabSplit[1] ;
} ; # fin si
} ; # fin si
$nom = strtoupper($nom) ;
echo "Affichette : prénom = $pre ; nom = $nom\n\n" ;
# 3. préparation des noms de fichiers
$tmp = "/tmp/" ;
$baseFichier = tempnam($tmp,"affichettePHP") ;
$fichLatex = $baseFichier.".tex" ;
$fichPdf = $baseFichier.".pdf" ;
$fichLog = $baseFichier.".log" ;
# 4. écriture du code LaTeX
$codeLatex = file_get_contents("affichette_debut.latex") ;
$codeLatex .= "\\affichette{".$pre." ".$nom."}\n" ;
$codeLatex .= "\\end{document}\n" ;
file_put_contents($fichLatex,$codeLatex) ;
# 5. exécution de pdflatex
$cmd = "( cd $tmp ; pdflatex -interaction=nonstopmode $fichLatex > /dev/null ) " ;
system($cmd) ;
# 6. affichage final
if (file_exists($fichPdf)) {
echo "Vous pouvez utiliser le fichier $fichPdf \n\n" ;
} else {
echo "Erreur de compilation. Consulter le fichier $fichLog pour voir l'erreur.\n\n" ;
} # fin si
?>
sachant que le début du fichier LaTeX à utiliser est dans le fichier affichette_debut.latex.
La page Web à réaliser pour automatiser ceci, soit affichette.php ne présente aucune difficulté car il s'agit juste de lire les noms, prénoms et insérer autant d'appels de la macro LaTeX que de personnes...
6. Production de documents pour une liste d'émargement
On dispose d'une liste d'émargement comme le fichier emarge.txt dont le format est très simple : chaque ligne non vide qui n'est pas un commentaire (repéré par le symbole dièse) comporte une information prénom puis une information nom. Un point virgule sépare ces deux informations qui sont parfois composées de plusieurs mots.
Question 6.1 : production d'un document CSV pour Microsoft Excel via PHP
Ecrire un programme PHP en CLI qui admet comme seul paramètre le nom d'un fichier et qui produit une liste d'émargement pour Microsoft Excel au format nom (en majuscules), prénom et signature.
Question 6.2 : production d'un document RTF pour Microsoft Word via PHP
Ecrire un programme PHP en CLI qui admet comme seul paramètre le nom d'un fichier et qui produit une "belle" liste d'émargement pour Microsoft Word au format numéro, nom (en majuscules), prénom et signature.
Pour plus d'informations sur RTF on pourra consulter l'exercice 1 de nos cours sur l'archivage.
Question 6.3 : production d'un document LaTeX via PERL
Ecrire un programme perl en CLI qui admet comme seul paramètre le nom d'un fichier et qui produit une "belle" liste d'émargement en PDF via LaTeX.
Question 6.4 : production d'une liste d'émargement via une page Web
Ecrire une page Web en PHP qui demande via un formulaire le nom d'un fichier et une valeur d'option (W, E ou L) et pour produire une "belle" liste d'émargement respectivement pour Microsoft Word, Microsoft Excel ou PDF (via LaTeX) suivant la valeur de l'option.
On organisera ce programme à l'aide de sous-programmes et de fichiers-inclus afin d'en faire ensuite rapidement une page Web avec un formulaire où le nom du fichier est remplacé par la saisie des données dans un <textarea> ou par la sélection du fichier dans l'explorateur sous-jacent. On réfléchira aussi à ce qu'il faut ajouter pour fournir une "vraie" liste d'émargement utilisable.
Hélas, à ce jour (2016), aucun étudiant ni aucun internaute averti n'a fourni de solution complète satisfaisante.
Voici quelques éléments partiels de réponses...
Réponse 6.1 : production d'un document CSV pour Microsoft Excel via PHP
Une liste d'émargement n'est jamais qu'un tableau à trois colonnes. Ici, tout est déjà presque prêt puisque le découpage en nom est repérable grâce à un point virgule. Comme le "vrai" séparateur est la virgule pour le "vrai" format CSV, il reste juste à mettre le nom des colonnes en début de fichier, inverser nom et prénom et passer le nom en majuscule. Ce genre de traitement s'effectue plus facilement ligne à ligne que globalement et c'est pourquoi nous n'utilisons pas ici la fonction file_get_contents de PHP.
Le programme solution est ici et fournit, pour le fichier exemple emarge.txt, la feuille d'émargement nommée emarge_php.csv. Il n'y a sans doute pas besoin de numéroter les noms et prénoms, vu qu'Excel et Open Office Calc affichent systématiquement des numéros de ligne. Par contre le format des cellules laisse à désirer, d'où la réponse à la question suivante.
Réponse 6.2 : production d'un document RTF pour Microsoft Word via PHP
Un fichier au format RTF n'est jamais au fond qu'un fichier texte avec des marqueurs { et }. Le plus simple est sans doute de mettre au point sous Word la mise en forme souhaitée puis de recopier l'en-tête (fixe) avant de programmer la partie variable (chacune des lignes du tableau).
Le programme solution est ici et fournit, pour le fichier exemple emarge.txt, la feuille d'émargement nommée emarge_php.rtf. Dans la mesure où les balises RTF sont écrites en minuscules, nous avons choisi de mettre dans la partie variable les mots variables en majuscules (voir ci-dessous) afin de pouvoir les remplacer facilement par les "vrais" noms et prénoms.
Affichage restructuré de l'extrait RTF
--------------------------------------
\pard \ltrpar\ql \li0\ri0\sb120\sa120
\widctlpar\intbl\aspalpha\aspnum\faauto
\adjustright\rin0\lin0\pararsid11798960
{\rtlch \af0 \ltrch \lang2057\langfe1036\langnp2057
\insrsid11798960\charrsid5799530 NUM \cell }
{\rtlch \af0 \ltrch \lang2057\langfe1036\langnp2057
\insrsid11798960\charrsid5799530 NOM }
{\rtlch \af0 \ltrch \lang2057\langfe1036\langnp2057
\insrsid11798960\charrsid5799530 \cell }
{\rtlch \af0 \ltrch \lang2057\langfe1036\langnp2057
\insrsid11798960\charrsid5799530 PRENOM }
{\rtlch \af0 \ltrch \lang2057\langfe1036\langnp2057
\insrsid11798960\charrsid5799530 \cell \cell }
\pard \ltrpar\ql \li0\ri0\widctlpar\intbl
\aspalpha\aspnum\faauto\adjustright\rin0\lin0
{\rtlch \af0 \ltrch \lang2057\langfe1036\langnp2057
\insrsid11798960\charrsid5799530 \trowd \irow1\irowband1
\ltrrow\ts15\trgaph70\trleft-108\trbrdrt\brdrs\brdrw10
\trbrdrl\brdrs\brdrw10 \trbrdrb\brdrs\brdrw10 \trbrdrr
\brdrs\brdrw10 \trbrdrh\brdrs\brdrw10
\trbrdrv\brdrs\brdrw10 \trftsWidth1\trftsWidthB3
\trftsWidthA3\trautofit1\trpaddl108\trpaddr108\trpaddfl3
\trpaddft3\trpaddfb3\trpaddfr3\tbllkhdrrows\tbllklastrow
\tbllkhdrcols\tbllklastcol \clvertalt\clbrdrt\brdrs\brdrw10
[...]
\clshdrawnil \cellx6677\row }
Réponse 6.3 : production d'un document LaTeX via PERL
Le programme solution est ici et fournit, pour le fichier exemple emarge.txt, la feuille d'émargement nommée lstemarge.pdf. Notre programme PERL utilise des fonctions personnelles via le module nommé strFuncs.pm.
Réponse 6.4 : production d'une liste d'émargement via une page Web
Pour produire une "vraie" liste d'émargement utilisable, il faut sans doute ajouter un titre autre que «liste emargement», donner la possibilité d'utiliser la date du jour ou d'entrer la date à laquelle la liste doit être remplie, offrir la possibilité d'ajouter quelques lignes vides pour des personnes en surnombre...
7. Liste de fonctions pour documentation
Question 7.1
On dispose d'un code source, disons strfun.php et on veut la liste des fonctions du fichier, par ordre alphabétique, avec le numéro de ligne du début de la fonction. Quelle solution rapide en ligne de commandes Unix peut-on utiliser ?
Est-ce que les fonctions vectorielles de R fournissent une solution concise à ce problème ?
Question 7.2
On veut maintenant un affichage «propre», sans le mot function et avec un affichage formaté des numéros de ligne. De plus on voudrait disposer de toutes les fonctions en cas d'utilisation d'un fichier maitre avec des include ou des require. On utilisera PERL.
Rajouter des sorties Word (RTF), PDF (LaTeX) et XHTML, le choix du format se faisant à l'aide d'un paramètre -o ou --output.
Question 7.3
Ce serait bien de disposer aussi d'exemples pour chaque fonction et de passer par un affichage Web pour voir les fonctions à afficher. On implémentera comme d'habitude cela dans une page Web valide pour XHTML strict.
Question 7.4
Compléter le fichier strfun.php pour que la documentation soit au format Doxygen. Quels sont les avantages et les inconvénients de Doxygen par rapport à ce que nous avons développé ?
Pas encore ! A ce jour (2016), aucun étudiant ni aucun internaute averti n'a fourni de solution complète satisfaisante.
Voici toutefois quelques éléments de réponse.
Réponse 7.1 -- Commandes Unix
Pour trouver les numéros de ligne d'un fichier correspondant à un mot particulier, le système Unix fournit la commande grep avec le paramètre -n. On pourrait donc écrire pour détecter le mot function :
grep -n function strfun.php
Afin d'éviter de renvoyer des lignes comme "} # end of function" qui contiennent aussi le mot function, on peut essayer de détecter function écrit en début de ligne via le symbole ^ dans l'expression régulière de recherche :
grep -n "^function" strfun.php
Malheureusement, s'il y a des espaces devant le mot function les lignes correspondantes ne seront pas trouvées. Il vaut donc mieux écrire :
grep -E -n "^\s*function" strfun.php
Voici le résultat de l'exécution de cette commande
15: function copies($chen,$frep) {
31:function compteMots ( $phrase) {
61:function mot ( $phrase, $num) {
95:function nbmots ( $phrase) {
125:function premierCarNonNul( $chen ) {
150:function surncarg( $chen , $lng ) {
165:function surncard( $chen , $lng ) {
180:function surncardzero( $chen , $lng ) {
195:function surncardnbsp( $chen , $lng ) {
210:function nbdif( $seq1 , $seq2 ) {
On trouvera ici une page d'aide complète sur grep en français.
Il faut maintenant trier les lignes affichées et heureusement Unix fournit la commande sort. On pourrait penser utiliser la redirection des sorties via le symbole > soit le code
grep -E -n "^\s*function" strfun.php > listeFonctions.txt
sort listeFonctions.txt
mais ce n'est pas la peine car il est possible de chainer les commandes (la sortie d'une commande est l'entrée de la suivante) via le symbole | nommé pipe en anglais -- tuyau en français -- :
grep -E -n "^\s*function" strfun.php | sort
sort a bien effectué un tri, mais ce n'est pas celui que nous voulions :
125:function premierCarNonNul( $chen ) {
150:function surncarg( $chen , $lng ) {
15: function copies($chen,$frep) {
165:function surncard( $chen , $lng ) {
180:function surncardzero( $chen , $lng ) {
195:function surncardnbsp( $chen , $lng ) {
210:function nbdif( $seq1 , $seq2 ) {
31:function compteMots ( $phrase) {
61:function mot ( $phrase, $num) {
95:function nbmots ( $phrase) {
En fait, sort a trié selon l'ordre alphabétique des numéros de ligne. Ce qu'on voudrait, c'est trier selon le deuxième mot (ou champ ou clé, key en anglais). Pour cela, il faut utiliser le paramètre -k :
grep -E -n "^\s*function" strfun.php | sort -k 2
Et voilà le travail :
31:function compteMots ( $phrase) {
15: function copies($chen,$frep) {
61:function mot ( $phrase, $num) {
210:function nbdif( $seq1 , $seq2 ) {
95:function nbmots ( $phrase) {
125:function premierCarNonNul( $chen ) {
165:function surncard( $chen , $lng ) {
195:function surncardnbsp( $chen , $lng ) {
180:function surncardzero( $chen , $lng ) {
150:function surncarg( $chen , $lng ) {
On trouvera ici une page d'aide complète sur sort en français.
Ce n'est bien sûr pas très «propre». Pour avoir quelque chose de «bien beau, bien propre», on peut utiliser gawk par exemple avec le code suivant
grep -n "function" strfun.php | awk -f grep07.awk | sort -k 1,1
Le fichier awk correspondant, soit grep07.awk, vient juste réordonner les informations, avec d'abord le nom de la fonction puis le numéro de ligne, avec des formatages adaptés pour une meilleure lisibilité :
# on passe de la sortie brute de grep
#
# 15:function copies($chen,$frep) {
# 195:function surncardnbsp( $chen , $lng ) {
# 210:function nbdif( $seq1 , $seq2 ) {
#
# à une sortie plus propre et triée comme
#
# compteMots 31
# copies 15
# mot 61
# nbdif 210
# nbmots 95
# premierCarNonNul 125
# surncard 165
# surncardnbsp 195
# surncardzero 180
# surncarg 150
#
{ nomF = $2 ;
numL = $1 ;
sub("\\("," ",nomF) ;
split(nomF,tnomf) ;
nomF = tnomf[1] ;
sub(":function","",numL) ;
print " " sprintf("%-25s",nomF) sprintf("%5d",numL) ;
}
Réponse 7.1 -- Logiciel R
Le logiciel R dispose aussi d'une fonction grep() dans le package base qui ressemble très fortement à la commande Unix de même nom. Il suffit donc d'écrire, après la lecture du fichier par lignes <- readLines(fichier)
grep(pattern="^\\s*function", x=enc2utf8(lignes))
L'expression régulière utilisée ici ^\\s*+function est un tout petit peu plus compliquée
que la simple chaine ^function
car
-
il peut y avoir plusieurs espaces entre ^ et function
d'où la partie \s* ;
-
pour saisir un "slash" dans une expression régulière, il faut doubler ce symbole, d'où \\s* ;
Si de plus on utilise le paramètre value avec la valeur TRUE dans l'appel de la fonction grep(), R renvoie la chaine détectée. Voici ce qu'on
peut donc facilement obtenir avec R juste avec grep() et l'expression régulière :
> grep(pattern = "^\\s*function",lignes)
15 31 61 95 125 150 165 180 195 210
> grep(pattern = "^\\s*function",lig,value=TRUE)
[1,] "function copies($chen,$frep) {"
[2,] "function compteMots ( $phrase) {"
[3,] "function mot ( $phrase, $num) {"
[4,] "function nbmots ( $phrase) {"
[5,] "function premierCarNonNul( $chen ) {"
[6,] "function surncarg( $chen , $lng ) {"
[7,] "function surncard( $chen , $lng ) {"
[8,] "function surncardzero( $chen , $lng ) {"
[9,] "function surncardnbsp( $chen , $lng ) {"
[10,] "function nbdif( $seq1 , $seq2 ) {"
Pour ne garder que le deuxième mot de chaque ligne trouvée, on peut utiliser une fonction
anonyme. Voici donc le texte complet de la fonction qui construit la liste des fonctions d'un fichier-script :
listeFonctions <- function(fichier="") {
# test du paramètre et aide éventuelle
if (missing(fichier) | fichier=="") {
cat("\nsyntaxe : listeFonctions(fichier)\n")
return(invisible(""))
} # fin de si
stopifnot(file.exists(fichier)) # arrêt si le fichier n'est pas présent
lignes <- enc2utf8( readLines(fichier) ) # lecture du fichier + conversion en utf8
# détection des entêtes de fonction
expReg <- "^\\s*function"
numLignes <- grep(pattern=expReg,x=lignes)
foncLignes <- grep(pattern=expReg,x=lignes,value=TRUE)
fonctions <- sapply(FUN=function(x) { x[[2]][1]} ,X=strsplit(sub("\\("," ",foncLignes),split=" "))
# tri simultané des noms de fonctions et des numéros de lignes
idx <- order(fonctions)
fonctions <- fonctions[idx]
numLignes <- numLignes[idx]
# affichage
phrase <- paste("Liste des fonctions du fichier",fichier,collapse=" ")
soulign <- paste(rep("=",nchar(phrase)),collapse="")
cat("\n",phrase ,"\n",soulign,"\n\n")
matFonc <- cbind(sprintf("%6s",numLignes),paste(fonctions,"()",sep=""))
colnames(matFonc) <- c("numéros de ligne","fonctions")
print(matFonc,quote=FALSE)
} # fin de fonction listeFonctions
Et le rendu est bien conforme à ce qu'on voulait
Liste des fonctions du fichier strfun.php
=========================================
numéros de ligne fonctions
[1,] 31 compteMots()
[2,] 15 copies()
[3,] 61 mot()
[4,] 210 nbdif()
[5,] 95 nbmots()
[6,] 125 premierCarNonNul()
[7,] 165 surncard()
[8,] 195 surncardnbsp()
[9,] 180 surncardzero()
[10,] 150 surncarg()
Réponse 7.2 -- Programmation PERL
Détecter le mot function en début de ligne n'est vraiment un problème en PERL. Par contre pour passer en revue transitivement tous les include et require demande un toutpetit peu plus de réflexion. Voici le code complet :
# # (gH) -_- ldfPhp.pl ; TimeStamp (unix) : 23 Février 2016 vers 18:23
############################################################################
#
# ldfPhp.pl : liste des fonctions d'un module Php ; version 1 : (gH) 2008
#
############################################################################
$version_ldfPhp = 1.3 ;
use lib $ENV{"PERL_MACROS"} ; # répertoire qui contient mes macros
use strFuncs ;
#
# on détecte : include
# include_once
# require_once
# function
#
if ($ARGV[0] eq "") {
print "\n" ;
print " syntaxe : ldfPhp nom_de_fichier.php \n" ;
print "\n" ;
exit(-1) ;
} ; # fin de test sur les arguments
$fs = "ldfPhp.sor" ; # fichier de sortie
open( FS ,">$fs") || die "\n impossible d'écrire dans le fichier $fs\n\n" ;
$nomp = $ARGV[0] ; # nom du programme
if (! ( (-e $nomp) && (-r $nomp) ) ) { die "\n Impossible de lire dans le fichier $nomp\n\n" ; } ;
print "\n" ;
$msg = "Analyse du fichier $nomp" ;
print " $msg \n" ;
print FS " $msg \n" ;
print FS " ".("=" x length($msg))."\n" ;
print FS " ".&dateEtHeure()."\n\n" ;
print FS " Liste des fichiers inclus \n" ;
print FS " ------------------------- \n" ;
print FS " (format : nom du fichier et nombre de lignes dans le fichier) \n\n" ;
# on passe en revue le fichier et on cherche les inclusions
# puis les fonctions
@tdmar = split(" ","include( include_once( require_once(") ; # tableau des mots à rechercher
$lstFicTmp = " $nomp " ; # liste des fichiers
$lstFonc = " " ; # liste des fonctions
$lstFicVus = " $nomp " ; # fichiers déjà vus
while (&nbMots($lstFicTmp)>0) {
$nomf = &premierMot($lstFicTmp) ;
$nomf = trim($nomf) ;
if (length($nomf)>0) {
$lstFicTmp = &phraseSansPremierMot($lstFicTmp) ;
$lstFic .= $nomf." " ;
open(FC,"<$nomf") || die "\n impossible de lire dans le fichier $nomf\n\n\n" ;
$nblc = 0 ;
while ($lig=<FC>) {
$nblc++ ;
# 1. recherche d'inclusion
foreach $mac (@tdmar) {
$pdi = index($lig,$mac) ; # position de include ou assimilé
if ($pdi>-1) {
$ll = substr($lig,0,index($lig,')')) ; #
$dl = substr($ll,1+index($ll,'"')) ; # début de ligne
$nn = substr($dl,0,index($dl,'"')) ; # nom de fichier
$nn = &trim($nn) ;
if ($nn ne "once(") {
if (index(" $lstFicTmp "," $nn ")==-1) { # ajout éventuel
if (index(" $lstFicVus "," $nn ")==-1) { # ajout éventuel
$lstFicTmp .= " $nn" ;
$lstFicVus .= " $nn" ;
} ; # fin de si
} ; # fin de si
} ; # fin de si
} ; # fin si on a vu le mot à chercher
} ; # fin pour chaque
# 2. recherche du mot function
$mac = "function" ;
$pdf = index($lig,$mac) ; # position de function
if (($pdf>-1) && (&premierMot($lig) eq $mac)) {
$dl = substr($lig,length($mac)+1) ; # début de ligne
$nf = substr($dl,0,index($dl,'(')) ; # nom de fichier
$nf = &trim($nf) ;
if (index(" $lstFonc "," $nf ")==-1) { # ajout éventuel
$lstFonc .= " $nf " ;
$fdnbl{$nf} = $nblc ;
$sdnbl{$nf} = $nomf ;
} ; # fin de si
} ; # fin si on a vu le mot function
} ; # fin de tant que non fin de fichier sur FC
$tdnbl{$nomf} = $nblc ;
close(FC) ;
}
} ; # fin de tant que sur lstFic
# affichage des fichiers
@tabfic = sort split(" ",$lstFic) ;
print "\n" ;
$numf = 0 ; # nombre de fichiers
$nbl_t = 0 ; # nombre de lignes en tout
foreach $fic (@tabfic) {
$numf++ ;
$ls = " ".sprintf("%3d",$numf).". " ;
if ($fic eq $nomp) { $ls .= "*" ; } else { $ls .= " " ; } ;
$ls .= " ".surncarg($fic,20).sprintf("%6d",$tdnbl{$fic})."\n" ;
$nbl_t += $tdnbl{$fic} ;
print $ls ;
print FS $ls ;
} ; # fin pour chaque
print " total ".sprintf("%6d",$nbl_t)." lignes\n" ;
print FS " total ".sprintf("%6d",$nbl_t)." lignes\n" ;
print FS "\n" ;
# affichage des fonctions
print FS " Liste des fonctions (et position dans le fichier)\n" ;
print FS " --------------------\n\n" ;
$numf = 0 ;
foreach $fonc (sort split(" ",$lstFonc)) {
$numf++ ;
$ls = " ".sprintf("%3d",$numf).". " ;
$ls .= " ".surncarg($fonc,30) ;
$ls .= " ".surncarg($sdnbl{$fonc},30) ;
$ls .= " ".sprintf("%6d",$fdnbl{$fonc})."\n" ;
print FS $ls ;
} ; # fin pour chaque
print FS "\n" ;
# fonctions par fichier
foreach $fic (@tabfic) {
$ls = "Fonction(s) du fichier $fic" ;
print FS " $ls (et position dans le fichier)\n" ;
print FS " ".("-" x length($ls))."\n" ;
$numf = 0 ;
foreach $fonc (sort split(" ",$lstFonc)) {
if ($sdnbl{$fonc} eq $fic) {
$numf++ ;
$ls = " ".sprintf("%3d",$numf).". " ;
$ls .= " ".surncarg($fonc,30) ;
$ls .= " ".sprintf("%6d",$fdnbl{$fonc})."\n" ;
print FS $ls ;
} ; # fin de si
} ; # fin pour chaque
if ($numf==0) {
print FS " aucune fonction.\n" ;
} ; # fin de si
print FS "\n" ;
} ; # fin pour chaque
# affichages de fin
print "\n ... vous pouvez consulter $fs\n\n" ;
print FS "\n" ;
close(NP) ;
close(FS) ;
Voici un exemple de sortie pour la page Web qui correspond à l'URL Shspdb/index.php...
Réponse 7.3 -- Programmation PHP, fonctions et exemples
Nous avons déjà vu, avec std.php et statgh.r des exemples d'une telle page. Pour batir une telle interface, il faut bien sûr deux fichiers, celui du programme source, par exemple std.php et celui des exemples, comme stdphp.cmp pour les fonctions PHP, les fichiers statgh.r et statgh.xmp pour les fonctions R. Le code-source de chaque page est consultable via un lien en bas de chaque page. Il est court parce qu'il n'y a au départ pas grand-chose à faire, à savoir construire un élément textarea à gauche de la page avec la liste alphabétique des fonctions, l'affichage pour chaque fonction étant géré par Javascript.
Chaque fonction est consultable via l'url de la page et le paramètre lafns. Ainsi, avec l'URL
http://forge.info.univ-angers.fr/~gh/internet/stdphp.php?lafns=entetesTableau
il est possible d'arriver directement à l'affichage de la fonction entetesTableau.
Comment être sûr que chaque fonction est documentée, c'est-à-dire qu'elle a au moins un exemple ? Un simple programme PHP pour coupler les noms de fonctions définies et les appels de fonctions doit suffire, soit par exemple le programme PHP nommé stdphp_check.php suivant qui s'exécute en liugne de commande :
<?php
error_reporting(E_ALL | E_NOTICE | E_STRICT ) ;
include("std.php") ;
echo "Vérification des fonctions de statgh.php et des exemples\n" ;
# vérification de l'existence et ouverture des fichiers
$fns = "../std.php" ;
$xmp = "../stdphp.xmp" ;
$ff = @fopen($fns,"r") or die ("impossible de lire dans $fns.\n") ;
$fx = @fopen($xmp,"r") or die ("impossible de lire dans $xmp.\n") ;
$lesFns = file_get_contents($fns) ;
$lesXmp = file_get_contents($xmp) ;
# détection affichage du numéro de version
preg_match("/std\.php version (.*)/",$lesFns,$tRes) ;
echo " version de std.php lue : ".$tRes[1]."\n" ;
# extraction des fonctions et boucle sur leur exemple
# tableau des noms de fonctions
$tfns = array() ;
$nbfns = -1 ;
while ($lig=fgets($ff,4096)) {
if (substr(mot($lig."12345678",1),0,8) == "function") {
$nfns = mot($lig,2) ;
$pdp = strpos($nfns,"(") ;
$nfns = substr($nfns,0,$pdp) ;
$tfns[$nbfns++] = $nfns ;
} ; # fin de si
} ; # fin tant que
fclose($ff) ;
sort($tfns) ;
$numf = 0 ;
foreach ($tfns as $nfns) {
$numf++ ;
echo sprintf("%4d",$numf) ;
echo " fonction ".sprintf("%-20s",$nfns."()") ;
if (preg_match("/".$nfns."\((.*)/",$lesXmp,$tResX)) {
echo " vue via ".$tResX[0]."\n" ;
} else {
echo " NON VUE !\n" ;
} ; # fin si
} ; # fin pour chaque
echo "-- fin de vérification des fonctions de statgh.php et des exemples.\n\n" ;
?>
Réponse 7.4 -- Documentation Doxygen
Doxygen est un système de génération automatique de documentation via des codes spéciaux dans les commentaires. Le site officiel est ici et un tutoriel en français là.
Code-source de cette page ; fichiers inclus : pagsd_inc.php et pagsd.js.
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)