![]()
![]()
Solutions des exercices pour le cours
"TECHNOLOGIE INTERNET"
gilles.hunault@univ-angers.fr
Table des matières
cours 1 pages web, formulaires niveau 1
cours 2 "headers", formulaires niveau 2, scripts cgi
cours 3 pages web et Javascript
cours 4 applets java, niveau élémentaire
cours 5 intégration de html et php
cours 6 langage mysql et accès aux bases mysql via php
cours 7 html, xhtml et xml
Cours 1 : pages web, formulaires niveau 1 (énoncé)
Voir le code-source de la page principale du cours. Bien sûr, ce n'est pas la seule solution. Au lieu d'un tableau, on aurait pu utiliser une liste numérotée ou des sections disposées côte à côte. L'indentation fait ressortir les éléments et facilite une vérification humaine qu'il ne manque pas de balise.
On peut utiliser weblint (disponible en ligne de commande sous Forge) ou http://validator.w3.org sur le web, il y a aussi [CSE] Html validator, Max's Html beauty ou n'importe quel éditeur orienté HTML. Le plugin Htmlvalidator cité dans le cours peut aussi servir.
Une fois le DOCTYPE changé dans index.htm, on détecte 6 erreurs :
line 20 column 17 - Erreur: there is no attribute "background" line 34 column 9 - Erreur: there is no attribute "align" line 66 column 48 - Erreur: document type does not allow element "a" here; missing one of "p", "h1", "h2"... line 67 column 6 - Erreur: character data is not allowed here line 68 column 12 - Erreur: there is no attribute "color" line 68 column 21 - Erreur: element "font" undefinedVoir le code-source de la page index_strict.htm pour voir comment on a corrigé ces erreurs.
Afficher le code-source de la page tableau_ok.htm (commentaires en fin de fichier).
De même, les pages tableau.htm et tableau2.htm montrent comment réaliser les deux autres tableaux en "transitionnel".
Les solutions "strictes" sont nommées tableau_strict.htm et tableau2_strict.htm.
On peut utiliser checkbot ou Web Link Validator (payant) ou Xenu (gratuit). Le plugin Linkchecker cité dans le cours peut aussi servir.
Un navigateur sert à afficher. Dans la grammaire stricte, l'élément font n'existe pas. Un navigateur validant devrait donc soit refuser d'afficher la page soit ignorer cet élément. Si on teste la page font.php on constate que les navigateurs appliquent bien l'élément font et sa couleur, ce qui montre qu'ils ne respectent pas les consignes de la grammaire.
Il n'y aura sans doute jamais de 'navigateur validant de pages Web' car cela ne servirait à rien. Un navigateur sert à afficher. Par contre, dès qu'un navigateur trouve une erreur dans un document xml, il refuse de l'afficher. Démonstration ici.
Pour la comparaison entre XHTML et HTML 5, utiliser cmpDtd.
Voici les symboles affichés (consulter le code-source) : € £ Å ¶ Ø
On gère ces symboles via des entités dont une liste possible est à l'adresse : w3schools.
Pour faire vite il est judicieux d'avoir un modèle ou maquette ou skelette de page avec une commande exécutable pour charger un fichier du répertoire courant. Voici un exemple de squelette : skel.htm ; voici la commande d'appel de ce squelette pour mozilla avec son chemin d'accès complet :
mozilla file:///home/gh/public_html/internet/skel.htm & On définit bien sur un alias en deux ou trois lettres pour cette commande.
Consulter formulair.htm (version minimale) et boform.htm (version propre et valide XHTML).
SOURCE XHTML : boform.txt ; on remarquera que les styles s'appliquent aussi aux champs et même aux items de liste dans la liste de sélection des jours, que le nom "prénom" est utilisé deux fois (interdit en strict), que pour abonné, on n'a pas défini de valeur (le navigateur transmet "on"), etc.
Pour voir les styles en action, afficher la source de la page n_p1.htm ; une discussion plus fine est dans le document ti2005.pdf.
Pour justifier, utiliser le fichier std.css.
Pour valider une feuille de style, on peut utiliser w3c css-validator.
Le texte écrit par Microsoft Word est plus long, plus lourd, avec plein de "metas".
- le fichier courage.alamain contient une version minimale.
- le fichier courage.word97 contient le code HTML produit par Word 97.
- le fichier courage.word2002 contient le code HTML produit par Word 2002.
- le fichier courage.rtfstd contient le code RTF produit par Word 97.
- le fichier courage.rtfste contient le même code RTF en plus lisible.
(enfin, à peu près ; regarder de plus près la fin du fichier).Voici des références par ordre de complexité croissante pour HTML
- ccim
- ungi et peut-être dmc
- laltruiste
- http://fr.selfhtml.org/
En ce qui concerne les différences entre les navigateurs IE et Netscape, on peut consulter
http://developpeur.journaldunet.com/tutoriel/dht/020911_dom.shtml Pour les gens pressés, la "css_cheat_sheet" donne en anglais et en une page tout ce dont il faut se rappeler sur les styles. Version pdf : ici. Pour d'autres "refcards", cliquer là.
Maxthon est plus paramétrable que IE. Voir le site officiel.
Pour windows, lire http://www.ccim.be/ccim328/html/choix.htm : pour Linux, quanta et eclipse sont des choix "techniques mais raisonnables".
Il y a malheureusement une "pléthore" de logiciels, comme vous pourrez vous en rendre compte en feuilletant les liens suivants :
http://www.gratuiciel.com/freeware/pc/d0.htm
http://www.philgate.com/phil_Web/editeur.html
http://guide.ungi.net/htmledit.htmSi on se focalise sur les éditeurs prévus aussi pour php, ce n'est pas plus simple : regardez
http://cyberzoide.developpez.com/php4/editeurs Et si on s'intéresse aussi à XML, ce n'est pas mieux, comme le montre les liens :
http://xmlsoftware.com/editors.html
http://developpeur.journaldunet.com/tutoriel/out/050530-panorama-editeurs-xml.shtml
http://web.ccr.jussieu.fr/urfist/XML.htmDap (Download Accelerator Professional) est un outil de rapatriement en parallèle pour augmenter le rapatriement de fichiers sur Internet. Wget est un outils Dos, Windows et Unix pour rapatrier des pages webs, des sites complets... Pour un fichier MHT, il suffit de faire "Enregistrer sous..." avec IE. Lynx est un navigateur non graphique.
La balise pre permet de conserver les espaces et les retours chariots. La balise xmp (interdite en XHTML) recopie tel quel. La balise kbd utilise une police non proportionnelle. Avec le texte suivant
[ligne 1] . Bonjour (retour charriot) [ligne 2] . Et <font size="+3"><b>au</b></font> revoir !on obtient en mode pre
. Bonjour . Et au revoir !alors qu'on obtenait en mode xmp
et en mode kbd
. Bonjour . Et au revoir ! UTF8 et ISO8859 sont des encodages de caractères et de fichiers. Lire le détail dans http://www.afnic.fr/noncvs/formations/unicode_long/index.pdf (copie locale ici). Au passage, qu'est-ce que l'AFNIC ?
On ne peut pas extraire directement le n-ième caractère d'une chaine codée en Unicode car certains caractères au sens classique plusieurs autres caractères dits "combinatoire" comme le c-cédille.
Pour convertir, utiliser recode sous Unix ou iconv.
Pour voir facilement les couleurs, on peut utiliser colorpicker 3.1.
Il faut mettre dans target le mot _blank comme par exemple <a href="xmp.htm" target="_blank">xmp.htm</a> mais ce n'est pas du xhtml strict.
Consulter xmp_xhtml.htm ; les règles à respecter sont ici.
Une discussion plus fine est dans le document ti2005.pdf.
Après avoir consulté google_form qui contient une copie restructurée du formulaire de Google (datant d'octobre 2007), on voit clairement l'URL de base à utiliser, soit http://www.google.fr/search ainsi que le nom q du champ d'entrée et le paramètre caché meta à utiliser avec sa valeur cd=countryFR pour restreindre à la France.
Vérification : ici. A propos, connaissez-vous le site soople ?
Un "bon développement Web" repose sur quelques règles simples :
Toujours écrire des documents xhtml valides, pour la grammaire transitionnelle d'abord et pour la grammaire stricte si on en a le temps.
Pour les formulaires, mettre au point en mode GET puis passer en mode POST quand tout est au point.
Mettre, partout là où c'est possible, des liens relatifs.
Utiliser des feuilles de styles pas trop compliquées et vérifier le rendu sous IE et sous Firefox.
Mettre des icones pour prouver que la page est valide et penser à vérifier et à faire vérifier l'orthographe par d'autres.
Cette question n'a aucun sens. Meilleur par rapport à quoi ? Sans critère de jugement, tous les navigateurs se valent : IE parce qu'il est le plus répandu, Firefox parce qu'il est le plus configurable etc.
Les tests ACID ont pour but de vérifier à quel point les moteurs de rendu des navigateurs se conforment au W3C. En mai 2009, seul le navigateur Safari arrive à passer le test Acid3 à 100 %. Voir le test Acid3.
Le test Sunspider quant à lui, vient tester les performances de l'interpréteur Javascript. Enfin, le test peacekeeper teste aussi les fonctionnalités Javascript du navigateur.
Ajout 2016 : voir aussi browserscope.
En ce qui concerne les «parts de marché» des divers navigateurs, os, serveurs web et moteurs de recherche, on pourra se faire une idée relativement objective et précise de la situation à l'aide des liens suivants :
C'est une petite icone qui s'affiche devant l'URL dans la barre d'adresse. Voir par exemple ma page de départ. Elle s'obtient via <link rel='icon' type='image/png' href=... /> dans l'élément head. Ne pas hésiter à consulter le wiki français et le wiki anglais sur le sujet.
Cours 2 : "headers", formulaires niveau 2, scripts cgi (énoncé)
Afficher la source des pages diaporamas.htm, diapoa.htm et diapoa2.htm.
Un exemple plus complet avec mise à jour de 2 frames simultanément (via l'affichage d'une liste de fichiers lus dans un fichier liste [!]) est disponible ici.
Consulter ncbi.htm. Avez-vous remarqué que l'URL renvoyée, soit http://www.ncbi.nlm.nih.gov/protein/227778 ne correspond pas au numéro fourni (1710351A) ?
Voici quelques références
texte détaillé http://www.htmlhelp.com/fr/faq/html/forms.html perl/ssi http://fr.selfhtml.org/cgiperl/introduction/traitementformulaire.htm php http://www.manuelphp.com/php/language.variables.external.form.php Javascript (1) http://www.toutjavascript.com/savoir/savoir06_2.php3 Javascript (2) http://xlbysteph.free.fr/javascript/forms/formmasque.htm Javascript (3) http://www.toulouse-renaissance.net/c_outils/c_formcol.htm formulaires et Java http://www.univ-lemans.fr/enseignements/physique/02/java/java5.html Il faut commencer par tester le script en local, sans instruction HTML, c'est à dire écrire un programme "normal". Une fois qu'il est au point, il faut rajouter les instructions pour mettre du code HTML autour des affichages du programme. On peut alors effectuer une redirection de la sortie du programme vers un fichier HTML avant de tester avec le navigateur grace à la commande Fichier/Ouvrir
Enchainement des commandes à réaliser pour un script Perl :
emacs monprog.pl # édition perl monprog.pl # exécution perl monprog.pl > monprog.htm # redirection netscape file:///home/info/.../monprog.htm # visualisationEnchainement des commandes à réaliser pour un script Rexx :
sedit monprog.rex # édition rexx monprog.rex # exécution rexx monprog.rex > monprog.htm # redirection netscape file:///home/info/.../monprog.htm # visualisationVous n'êtes pas autorisé à écrire dans /scripts !
Vous n'êtes pas autorisé à écrire dans /scripts ! La solution aurait été : compte.sh ; la source est ici
Consulter images.sht et miniimages.zip; pour bien comprendre le script, on pourra exécuter les commandes en détail à la main les unes à la suite des autres en utilisant des fichiers intermédiaires.
On pourra consulter duree.pl qui fonctionne en ligne de commande.
Consulter exemple.php dont la source est ici ; on pourra noter que tout utilisateur sans droit particulier peut utiliser php dans son répertoire public_html si le serveur apache est bien configuré. Par contre pour l'interpréter, il faut passer par le protocole http:// même si on écrit la page en local. Sur la configuration du serveur (attention, un étudiant a un jour planté son portable avec ces commandes.... !) :
# Installations pour le serveur Web # et sessions X distantes + transferts de fichiers sudo apt-get install openssh-server sudo apt-get install proftpd # mode inetd conseillé sudo apt-get install lamp-server^ # mettre un mot de passe ! sudo apt-get install php5-gd sudo apt-get install php5-xsl sudo apt-get install php-pear # pour que mon ~/public_html soit vu en http://.../pub/MOI cd /var/www sudo mkdir pub sudo ln -s /home/MOI/public_html/ /var/www/pub/MOI # attention pour certains Ubuntu, il faut utiliser cd /var/www/html sudo mkdir pub sudo ln -s /home/MOI/public_html/ /var/www/html/pub/MOI # pour que http://.../~MOI soit accepté : sudo a2enmod userdir # pour les gens pressés : /etc/init.d/apache2 restart # mézalors les utilisateurs n'ont pas le droit aux .php # il y a une section à <<commenter>> dans /etc/apache2/mods-enabled/php5.conf : # (en fin de fichier) ## (gH) le 24 janvier 2009 pour autoriser les utilisateurs à exécuter du php ## attention : il faut COMMENTER ces lignes # <IfModule mod_userdir.c> # <Directory /home/*/public_html> # php_admin_value engine Off # </Directory> # </IfModule> ## mode debug pour PHP : # pour avoir les jolis affichage avec callstack en orange # sudo apt-get install php-pear # sudo pecl install xdebug # php --ri xdebug # il faut modifier /etc/php5/apache2/php.ini et avoir # display_errors=On et html_errors=On # puis relancer apache /etc/init.d/apache2 restartVous n'êtes pas autorisé à écrire dans /scripts !
Voir la solution de l'exercice numéro 3 pour la partie 1 du cours Sac/Farcompr. Pour vérifier que la solution fonctionne, sous Dos, Xp, Windows comme Unix, créer un répertoire et y décompresser l'archive alldsc.zip ; y recopier aussi le programme solution alldsc.pl et à la fin de l'exécution de la commande suivante (sans oublier le point en fin de ligne)
perl alldsc.pl .consulter le fichier RTF qui a été créé...
Voir le code-source de menuinternet.htm qui pour une fois n'est pas du xhtml mais du HTML valide ; la feuille de style utilisée est nommée menu.css et on remarquera que le menu reste fixé à gauche de la page avec Firefox et Opera, mais qu'il disparait sous IE7.
Voir l'afichage via votre navigateur de css.php.
Sans utiliser Javascript, il est possible de faire des "choses propres" avec CSS, mais en acceptant de charger des pages différentes. Voir le code-source de google2009/firefox2.html par exemple.
Voir le code-source et la feuille de style de menu.htm.
Beaucoup de choses : son adresse IP, son système d'exploitation, sa résolution écran, son fournisseur etc.
Voir la démonstration sur le site de la CNIL.
Navigation CNIL : sélectionner Vos libertés, puis Vos traces puis Votre ordinateur.
Couplé à une géolocalisation, ce genre de technique permet d'obtenir un "flicage" digne d'un film :
Ce programme exécute la commande Unix nommée df mais en plus calcule la somme des tailles affichées. Voici ce qu'affiche par exemple df :
Sys. de fich. Tail. Occ. Disp. %Occ. Monté sur /dev/sda5 14G 10G 2,8G 79% / varrun 1014M 168K 1014M 1% /var/run varlock 1014M 0 1014M 0% /var/lock udev 1014M 112K 1014M 1% /dev devshm 1014M 0 1014M 0% /dev/shm lrm 1014M 33M 981M 4% /lib/modules/2.6.22-16-generic/volatile /dev/sda6 14G 11G 2,6G 80% /home /dev/sda8 13G 11G 1,4G 89% /home/sup /dev/sda1 20G 18G 1,7G 92% /media/sda1 /dev/sda2 7,9G 7,4G 450M 95% /media/sda2 /dev/sda3 24G 24G 758M 97% /media/sda3Et voilà ce qu'affiche dfgh pour le même fs :
dfgh : comme df -h mais avec le total des tailles on exécute : df --portability --human-readable 1 : Sys. de fich. Tail. Occ. Disp. %Occ. Monté sur 2 : /dev/sda5 14G 10G 2,8G 79% / 3 : varrun 1014M 168K 1014M 1% /var/run 4 : varlock 1014M 0 1014M 0% /var/lock 5 : udev 1014M 112K 1014M 1% /dev 6 : devshm 1014M 0 1014M 0% /dev/shm 7 : lrm 1014M 33M 981M 4% /lib/modules/2.6.22-16-generic/volatile 8 : /dev/sda6 14G 11G 2,6G 80% /home 9 : /dev/sda8 13G 11G 1,4G 89% /home/sup 10 : /dev/sda1 20G 18G 1,7G 92% /media/sda1 11 : /dev/sda2 7,9G 7,4G 450M 95% /media/sda2 12 : /dev/sda3 24G 24G 758M 97% /media/sda3 taille totale : 97.0GEn principe, il vaut mieux utiliser des petites images (des vignettes) et ne mettre un lien que sur une "grosse image" qui sera affichée seule sur une page. Générer de nombreuses vignettes ou les générer à la volée n'est pas forcément une manipulation simple ou facile à effectuer mais c'est obliatoire si on de nombreuses images car Firefox ne chargera certainement pas en mémoire 500 Mo d'images...
Comme le montre la page française du Wiki à ce sujet, HTML5 comporte de nombreux changements par rapport à HTML4. Couplé à CSS3 (wiki fr) -- mais voir aussi CSS3 (wiki en) pour la partie Limitations -- HTML5, plus que XHTML5, est le langage d'écriture des sites web «modernes et récents». Grâce au responsive web design, l'affichage est prévu pour s'adapter aux différents types d'écrans des ordinateurs, tablettes, téléphones et autres smartphones. Le framework Bootstrap est un ensemble de classes CSS3 justement prévu pour cela et Bootply est un éditeur en lignes de pages Web via du copier/coller qui utilise Bootstrap. Pour apprendre HTML5, CSS3 et Boostrap, le plus simple est sans doute de passer par les tutoriels de w3schools.
La réponse à la question »Faut-il passer à HTML5, XHTML5 et CSS3 ?« est sans doute Oui, au moins pour HTML5 et CSS3 si on crée un nouveau site. Pour un site déjà en place, ajouter du CSS3 est sans doute un plus, mais basculer vers HTML5 peut demander beaucoup d'efforts, surtout s'il y a beaucoup de pages Web à reprendre...
Cours 3 : pages web et Javascript (énoncé)
Voir le fichier nombres.htm dont la source est ici.
Javascript doit servir à une gestion dynamique éventuelle de la page. Il vaut mieux créer des objets et insérer du contenu via DOM ; window.document.write ne devrait servir qu'en entrainement à la programmation en javascript pour éviter des appels fastidieux et répétitifs à la fonction alert.
Une solution plus propre en XHTML strict est ici et le fichier Javascript utilisé est là.
Pour une modification dynamique d'éléments via javascript, consulter l'exercice 2 du TP4 de mon cours en L2.
Voir la solution approximative formulairejs.htm dont la source est ici qui ne montre que les modes de "soumission". Une solution (un peu plus) propre est formulairejsok.htm et une solution "pro" sera fournie plus loin...
De même qu'il y a la balise <SCRIPT> il existe la balise <NOSCRIPT>. Voir le fichier testjs.htm dont la source est ici. (penser à vérifier que vous savez désactiver Javascript pour voir les deux affichages).
S'il s'agit juste de charger par URL une page différente en fonction de l'activation de Javascript, il n'y a pas besoin de passer par <SCRIPT> et <NOSCRIPT> car javascript peut "intercepter" l'URL (voir plus bas).
La notion de version de Javascript n'a aucun sens et ne serait pas très utile, vu que les différents navigateurs implémentent des langages Javascript différents. Une détection des propriétés du Javascript sous-jacent au navigateur est beaucoup plus "fonctionnelle".
Cela dépend du navigateur. Au vu de l'URL javascript:, à une certain époque, Firefox ouvrait une fenêtre de debug qui montrait seulement les erreurs de Javascript. Aujourd'hui on ouvre plutôt cette fenêtre avec le menu Outils/Console d'erreurs ou on utilise Firebug. De même, avec Opera, on affiche la console d'erreur via le menu Outils/Avancé ou on utilise Dragonfly.
Par défaut, c'est forcément le code-source "à froid" donc sans exécution de Javascript qui est analysé. Heureusement, HTML Validator permet d'analyser aussi le code généré par Javascript.
L'erreur est d'avoir mis l'apostrophe telle quelle ce qui ferme trop tot l'instruction write. Pour afficher une "quote", il faut mettre \ devant l'apostrophe.Le texte correct est donc :
window.document.write(' Qui le dit ? C\'est moi ! ') ; ****A l'affichage, l'instruction write incorrecte est simplement ignorée : il est difficile de se rendre compte qu'il manque quelquechose. Il est donc conseillé d'utiliser la console d'erreurs de javascript avec Firefox pour tester les scripts écrits en Javascript (lorsque cela fonctionne). Une solution "propre" consiste à utiliser Firebug avec Firefox dont une version "lite" existe même pour Internet Explorer. Pour Opera, on utilisera Dragonfly.
Voici ce qu'affichent les consoles d'erreur d'Opera et de Firefox quand on charge la page (images cliquables) :
Cela ne joue pas sur la validation qui se fait sur le code HTML au chargement (donc avant exécution du Javascript).
Voici quelques références :
- javascript index
- selfhtml
- Introduction à Javascript en français
- Tout javascript !
- listes de ressources Javascript
- liste de guides de référence
- javascript Guide JS 1.5
En particulier jalix est une bonne référence pour comprendre la différence entre Java et Javascript en termes d'objets et savoir13 montre bien la hiérarchie des objets liée à une page Web avec ses deux pages détail_1 et détail_2. Ce site fournit aussi un index interactif.
Ecmascript est un langage de programmation équivalent à Javascript mais qui fonctionne en dehors des navigateurs Web. FESI est un interpréteur Javascript/Ecmascript pour Windows, pour Unix. On peut aussi utiliser spidermonkey(l'exécutable se nomme js), rhino, see (Simple ECMAscript Engine)...
Il y avait en (en 2004) quelques éditeurs et environnements considérés comme "les meilleurs" : et dont les liens ne fonctionnent sans doute plus :
Le mieux est donc de chercher avec Google : soit javascript+editor soit éditeur+javascript ; on lira avec intérêt la page IntelliJ IDEA Javascript Editor qui, comme le graphique ci-dessous, détaille ce que doit être un tel éditeur :
Vérifiez que la page solution est bien capable de modifier le contenu de 2 cadres à la fois puis consultez les sources des pages utilisées... Par contre, cela ne peut pas être XHTML valide, ni en trans, ni en strict. Dommage...
Une lecture attentive des pages et un bon entrainement à la programmation permettent de comprendre les scripts...
Voir ti2005.pdf pour la fonction ecritSite().
Pour la fonction dd, voir dd.js. Ecrire dd("bonjour") est beaucoup plus court que d'écrire window.document.write('<dd>+"bonjour"+'</dd>') ; c'est aussi plus lisible, et cela garantit que les balises sont bien ouvertes et fermées.
Mais cela reste quand même du "bricolage". Avec document.CreateElement("dd"), on dispose d'un vrai élément, géré directement en mémoire par le navigateur...
La syntaxe correcte est <script type='text/javascript' src='fic.js'></script> pour le chargement des fonctions du fichier fic.js> et <script type='text/javascript'>f(a,b,c...)</script> pour l'appel de la fonction f avec les paramètres a, b>, c... Sinon on peut utiliser du CDATA mais c'est "mauvais"...
Voir validejs.htm avec en particulier son style valpers.css et son script valpers.js.
Le script ne voit aucune valeur parce qu'il n'y pas de nom (attribut name) dans le formulaire. L'attribut id sert au DOM/navigateur du document et est accessible par Javascript alors que name permet au serveur d'accéder aux variables renvoyées. On pourra aussi consulter le site (XHTML valide en strict) batraciens pour les changements de style dynamiques.
Avec type='texte' le type est incorrect ; le navigateur ignore donc type et met type='text' par défaut ; avec type='_submit_' pareil, mais ce coup-là ce n'est pas ce qu'on voulait. action='#' correspond à l'adresse du fichier du formulaire, mais avec une indication de section vide. Le navigateur exécute l'action donc il recharge la page et remet la valeur par défaut. Nombre est différent de nombre en javascript. Il y a donc erreur et Javascript s'arrête avant de passer sur return false. Donc return false n'est pas exécuté et l'URL dans action est chargée.
Pour une création dynamique, voir jscreadyn.htm. Pour les puristes de la création dynamique, voir jscreadyn2.htm. Les sources Javascript sont évidemment jscreadyn.js et jscreadyn2.js.
Comme son nom l'indique, un élément input type='text' n'est pas un nombre, mais une chaine de caractères. Donc le programme compare "3" et "12" (un peu comme "C" et "AB"). La réponse fournie est donc juste. Dans le code Javascript, il faut mettre parseInt... Vérification ici.
Consulter tableau2sol.htm. Il suffit de charger sorttable.js dans l'élément head puis d'ajouter class='sortable' à l'élément table pour qu'on puisse trier les colonnes. Ce qui est dommage, c'est qu'il faille ajouter un style pour qu'on remarque que le tableau puisse être trié. On pourra consulter la page de l'auteur du code-source en Javascript. Par contre, on ne peut pas trier les lignes. On appréciera la longueur du code source javascript et sa complexité, de même que la définition des itérateurs foreach...
Il y a marqué button au lieu de submit pour les input cliquables...
ParseInt devrait toujours être utilisé avec la base 10 dans les formulaires courants. Il faut donc mettre parseInt(x,10) au lieu de parseInt(x). La preuve ici. Il semblerait qu'Opera utilise la base 10 par défaut mais IE et Firefox la base 8 si la chaine commence par zéro...
Consulter le code-source de sen_eux_et_nous.php et son fichier de script sen_eux_et_nous.js. Le corrigé fournit une solution avec un tableau, puis avec des divisions sans CSS et enfin avec des divisions en CSS ; le script fonctionne avec IE et FF comme indiqué en commentaires.
Ce n'est pas vraiment "conceptuel" mais cela peut aider à gagner du temps, assurer que les éléments ont à la fois une balise fermante et une balise ouvrante, etc. Mais si Javascript n'est pas activé, l'utilisateur ne verra rien. Voici un exemple de code source possible et la page (horrible !) qui va avec, nommée h1.htm :
function wdw(x) { window.document.write(x) } // ############################################# function h1(x) { texth1 = "<h1>" + x + "</h1>\n" ; wdw( texth1 ) ; } ; // fin de fonction h1 // ############################################# function h2(x) { var elt = document.createElement("h2"); var h2txt = document.createTextNode("bonsoir") ; document.body.appendChild(elt) ; elt.appendChild(h2txt) ; } ; // fin de fonction h2 // #############################################Dans la page cota.php, le fichier javascript cota.js permet de permuter les textes sur fond de couleur ou juste les adjectifs. Le dernier lien (sur onmouseover) montre la différence d'interaction entre le pseudo-format hover et l'évènement onmouseover. Telle quelle, la page ne permet pas d'accèder au lien si Javascript est actif.
Oui et Non. Oui, on peut animer des objets, mais non, ils ne sont pas exactement dans une page Web. On peut avec Javascript animer des objets définis dans un graphique SVG (fichier XML) et au lieu d'utiliser document.getElementById on utilise svgDocument.getElementById à condition de définir svgDocument via evt.target.ownerDocument où evt désigne l'élément géré. Voir par exemple bougeObjets et orbitesPlanétaires.
Puisque des navigateurs différents ont des Javascript différents, un numéro de version seul n'a aucun intérêt. Il vaut mieux tester si la fonctionnalité qu'on veut utiliser est définie ou pas.
Consulter ta.html pour le remplissage.
Il est possible de lire un fichier pour l'inclure dans le textarea, voir par exemple notre page webrd01 qui utilise webrd.js.
Angular, jQquery et prototype sont sans doute les «plus grands». De façon indirecte, underscore est sans doute une librairie Javascript intéressante, à défaut d'être un framework. Pour apprendre Angular et Jquery, le plus simple est sans doute de passer par les tutoriels de w3schools.
Node.js dont le site officiel est https://nodejs.org/ permet d'exécuter du Javascript du coté serveur et donc de concurrencer des systèmes LAMP comme serveurs Web. Voir openclassrooms (fr) et le wiki français pour en comprendre les avantages.
Cette page affiche les titres de films contenus dans le fichier films2.xml via la technologie AJAX à l'aide de JQUERY.
Cours 4 : applets java, niveau élémentaire (énoncé)
(non maintenu car non enseigné depuis 2011).
Pour tester une applet hors navigateur, on peut utiliser le programme appletviewer. qui est en principe installé en standard avec le jdk ou le jre utilisé pour compiler le programme java.
Vous pouvez utiliser les pages suivantes
Applet minimale nbm1 (divers affichages d'un texte) source de la page nbm1 ; source des applets. Applet nbm2 qui affiche un nombre aléatoire source de la page nbm2 ; source de l'applet. Applet nbm3 qui demande un nombre et utilise un bouton source de la page nbm3 ; source des applets. Applet complète nbm source de la page nbm ; source de l'applet.
Il existe de nombreuses références. Laquelle choisir est une affaire de gout. Je conseillerais :
- la documentation en ligne de Java chez Sun
- le site penser en java avec textes anglais et français en regard
- le "java corner" suisse (et en français)et aussi, cités sur la page du cours :
- des exemples de mini-applets pour tout faire
- les applets : petit cours par Isabelle Thieblemont
- les applets : cours de l'Université du Mans
Là encore, il y a de nombreux environnements.
Celui nommé BlueJ, gratuit et en français qui correspond au livre Conception objet en Java avec BlueJ me semble être un bon choix. Pour plus de détails, voir le livre de Barnes / Kolling chez l'éditeur Pearson. Téléchargement de bluej (anglais) et tutoriel (français).
L'environnement netbeans de Sun vaut aussi le détour.
Tout d'abord, il faut repérer où Javascript est utilisé.
Une lecture attentive du formulaire permet de voir que Javascript est utilisé 3 fois, à chaque clic proposé pour les boutons du formulaire soit les instructions :
onclick="document.cpt.setCouleur('bleu')"> onclick="document.cpt.setCouleur('rouge')"> onclick="resuapplet.value=document.cpt.getCompteur()">Dans les deux premiers cas, on communique directement avec l'applet alors que dans le troisième cas, on met comme valeur dans le champ texte du formulaire le résultat de l'exécution de la fonction java nommé getCompteur.
Cours 5 : intégration de html et php (énoncé)
Il faut utiliser la fonction phpversion ; par exemple on peut écrire :
<?php echo 'la version de php est : '.phpversion() ?>Pour plus de détails sur la configuration de php utilisée, il existe une instruction (qui n'est pas une fonction) nommée phpinfo, soit le code
<?php phpinfo() ?>Une instruction fait partie du langage alors qu'une fonction peut être inventée par un utilisateur. De plus certaines fonctions n'affichent rien mais renvoient une valeur, comme phpversion(). Ce n'est donc qu'une partie d'une instruction...
Test ici et là respectivement pour les serveurs forge et pegase.
Source de la page ; on remarquera qu'on n'écrit même pas <HTML> ni <HEAD> et qu'en plus le code produit est XHTML valide...
Lorsque l'installation le permet (par exemple avec PHP sous Linux comme pour forge) PHP peut s'utiliser en ligne de commande. Cela permet de tester les scripts sans passer par les formulaires, de mettre au point des objets, des sous-programmes... On peut alors utiliser PHP comme un interpréteur classique de programmes. Les paramètres passés sont alors dans le tableau nommé (comme d'habitude !) $argv et leur nombre dans $argc. Voici un exemple complet de syntaxe d'appel avec redirection de sortie : php monProgramme.php 18 oui 21 32 > resultats.txt .
Sous Linux/Ubuntu si on tape php -a alors on peut dialoguer avec PHP, tester rapidement la syntaxe d'une fonction...
Un autre intérêt des options de PHP en ligne de commande (consultables ici sous Linux et là pour Windows) est de vérifier la syntaxe du texte PHP ; avec un navigateur, souvent la page est vide en cas d'erreur ; en ligne de commande on a des messages explicites comme :
PHP Parse error: unexpected '>' in /home/info/gh/public_html/internet/test.php on line 222 PHP Parse error: parse error, unexpected T_ECHO, expecting ',' or ';' in /home/info/gh/public_html/internet/validation.php on line 647En effet, certains serveurs sont configurés pour ne pas afficher les erreurs d'exécution. Ce qui est très gênant car on ne se rend pas toujours compte que le programme php est fini. Voici la différence entre un serveur qui n'affiche pas les erreurs (S1), un serveur qui affiche les erreurs (S2 et S3) et ce qu'on aurait du obtenir (S3). Les images sont cliquables :
S1 S2 S3 S4 En ligne de commande, il y a passage à la ligne à chaque \n, comme pour le code-source de la page Web. Dans la page Web, seuls les balises comme <br />, <p>, <tr>... passent à la ligne. Remarque : il n'y a donc aucun rapport entre les numéros de lignes du programme php et les numéros de lignes de la page affichée. La page principale du formulaire de Google par exemple (soit source) contient un code-source qui n'a presque pas de retour à la ligne lisble...
Les retours à la ligne dans une page Web sont obtenus par les éléments p, br, hr, les tr des tableaux et les divisions, ou par style CSS. Les retours à la ligne dans le source viennent des "\n" écrits par PHP.
On met dans cet ordre l'URL puis les paramètres puis la section. Ainsi on doit écrire http://deneb.info-ua/~gh/internet/solutions.php?ref=1628#php.
Fichiers solutions à consulter :
demandenb1.php Formulaire sans validation source validenb1.php Validation sans vérification source demandenb2.php Formulaire avec validation source validenb2.php Validation avec vérification source La solution a déja été donnée en 4.
L'intérêt, c'est de rester au niveau des fonctions php et de fermer systématiquement les balises. De plus il est plus court d'écrire h1("Bonjour") ; que echo "<h1>Bonjour</h1>\n" ;\n et c'est aussi plus lisible.Voici deux définitions de h1 donc une seule est "propre" :
function h1($chen=" ") { echo "<h1> $chen </h1>\n" ; } ; # fin de fonction h1 function h1($chen) { echo "<h1>$chen</h1>" ; } ; # fin de fonction h1Il serait tout aussi "conceptuel" et "développeur" de regrouper les fonctions h1($txt) et h2($txt) en une seule fonction h paramètrée telle que h1($txt) corresponde à h(1,$txt) et h2($txt) à h(2,$txt) à condition de n'utiliser que les fonctions h1() et h2().
Si on compare les solutions validenb1.php, validenb2.php et validenb3.php il est clair que la troisième est la plus courte à lire...
Les fonctionnalités évidentes correspondent à la saisie et au stockage du nom, du prénom, de la date et de l'heure de soutenance.
Après quelques essais, on se rend compte qu'il n'est pas possible d'utiliser le même couple (date/heure) pour des personnes différentes et que si on rentre la même personne la date et l'heure sont changées pour cette personne. En d'autres termes, une même personne ne peut pas réserver plusieurs créneaux.
Une fonctionnalité cachée est la possibilité de réinitialiser la base des horaires de soutenance via un couple (nom/prenom) bien choisi mais que pour des raisons de sécurité on ne donnera pas ici (démonstration en salle).
Ces fonctionnalités ne sont pas obligatoires mais choisies. Plus généralement, un programme PHP doit correspondre à des spécifications, à un CdCF (cahier des charges fonctionnnel), implémentant la solution décidée parmi toutes celles possibles. Ici, on pourrait autoriser la prise de plusieurs rendez-vous pour la même personne, imposer un mot de passe, envoyer un mail de confirmation, verrouiller les rendez-vous à une date fixe, relancer ceux qui n'ont pas pris rendez-vous etc.
PhpMyAdmin est une application écrite en PHP qui permet d'administrer, depuis un navigateur,des bases de données de type MySQL (une version PostgreSQL est aussi disponible) via une interface de type tableur. On peut également créer, modifier, supprimer des bases de données ou des tables, exécuter des requêtes SQL, exporter et importer des fichiers texte pour remplir les tables.
Pour plus de renseignements, consulter :http://www.phpmyadmin.net/ En voici une copie d'écran (cliquer pour aggrandir) :
PhpMyAdmin est pour MySql. Il y a bien sur phpPgAdmin pour PostgreSQL.
Il faut extraire les initiales de la variable $ldi et produire le texte :
<select name="num_med"> <option value="1"> JD </option> <option value="2"> EV </option> <option value="3"> HP </option> </select>On peut réaliser cela avec les instructions php suivantes :
$ldi = "JD EV HP" ; $tdi = split(" ",$ldi) ; # $tdi = preg_split("/\s+/",(trim($ldi))) ; si espaces multiples $num = 0 ; echo "Choisissez l'initiale du médecin " ; echo "<select name='num_med'>\n" ; foreach ($tdi as $initiales) { $num++ ; echo "<option value=\"$num\"> $initiales </option>\n" ; } ; # fin pour chaque echo "</select>\n" ;Vous pouvez consulter le code-source de la solution et son affichage.La fonction include permet de lire un autre fichier PHP ; on s'en sert classiquement pour lire des sous-programmes communs. Démonstration
appel.php programme appelant source sousprog.php sous programme appelé (on voit rien au chargement) source On notera que les deux scripts PHP ne contiennent aucune "instruction" HTML.
Un fichier PHP pour définir le début d'une page Web en une ligne est gen.php.
Voir le code-source de php_concept1.php puis le code-source de php_concept2.php pour des utilisations des fonctions proposées. Pour la deuxième partie de l'exercice, consulter conceptuel4.php.
Le code PHP proposé appelle la fonction debutPage avec le titre (élément title) fourni en paramètre 1. La grammaire demandée est la grammaire stricte et il faut charger dans cet ordre les feuilles de styles f1.css et f2.css ; enfin, on charge les trois fichiers de script s1.js, s2.js et init.js, soit le code HTML suivant :
<?xml version="1.0" encoding="ISO-8859-1" ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" lang="fr" xml:lang="fr"> <head> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" /> <script type='text/javascript' src='s1.js'></script> <script type='text/javascript' src='s2.js'></script> <script type='text/javascript' src='init.js'></script> <link rel="stylesheet" type="text/css" href="std.css" title="gh" /> <link rel="stylesheet" type="text/css" href="f1.css" title="gh" /> <link rel="stylesheet" type="text/css" href="f2.css" title="gh" /> <title> Voir le code-source php</title> </head> <body class="beige_jpg"> <blockquote> <p> </p> <p class='align_right'> <a href="http://validator.w3.org/check?uri=referer"> <img src="valid.png" height="31" width="88" alt="Valid XHTML" /> </a> <a href='http://jigsaw.w3.org/css-validator/validator?uri=http%3A%2F%2Fforge.info.univ-angers.fr%2F%7Egh%2Fstd.css'> <img src="css.gif" height="31" width="88" alt="Valid CSS2" /> </a> </p>Références en français :
documentation http://www.nexen.net/ http://www.manuelphp.com/ http://php.net/ formulaires http://www.phpindex.com/ bases de données http://laurent.fagot.free.fr/ éditeur http://cyberzoide.developpez.com/php4/editeurs/ La dernière référence de l'exercice précédent, à savoir :
http://cyberzoide.developpez.com/php4/editeurs/
peut suffire comme réponse.
On peut bien sur lire des fichiers en PHP via fopen et fgets à condition d'utiliser un or die... ou de tester avec file_exists que le fichier existe, car lire dans un fichier inexistant pose toujours problème... Au passage, on remarque ici l'incohérence de nommage de file_exists par rapport à fopen, gfet, fclose. A titre d'exemple, consultez :
litfic.php script de lecture source brut.txt fichier texte lu lignes numérotées En ligne de commande, c'est vous qui êtes propriétaire des fichiers écrits. Par contre sur le Web, c'est le serveur, d'où des précautions d'écriture...
Remarque : Une page Web est un fichier, accessible par son URL. On peut donc ouvrir n'importe quelle page Web via fopen en PHP.
Pour écrire au lieu de lire, il faut changer le deuxième paramètre de fopen. Attention toutefois à ce que le répertoire doit être en écriture pour le groupe 'others', soit le chmod 777, ce qui n'est pas conseillé.
Par contre, il est toujours possible d'écrire dans le répertoire dit 'temporaire' du système (sans doute /tmp sous Linux). La fonction tempnam sert alors à rendre unique le nom du fichier pour le programme. Consulter tmpnam.php et sa source pour voir un exemple.
Une page Web (ou plutôt le fichier texte correspondant) dont on donne l'URL est considéré par PHP comme un fichier «normal» qu'on peut ouvrir avec fopen et lire avec fgets...
Trouver la liste des fonctions consiste simplement à chercher 'function' comme premier mot de la ligne. Voir listefns.php comme exemple de solution. On pourra aussi utiliser ldphp.pl (et son module strFuncs.pm) dont un exemple de sortie est ldphp.sortie.
On pourra également consulter le code-source de la page stdphp.php qui liste les fonctions du fichier.
Une session sert à conserver les valeurs des variables PHP à travers plusieurs pages. Si la page 1 initialise "bêtement" la variable a avec la valeur 1 et appele la page 2 alors cette page 2 ne connait pas la variable a. Par contre si la page 3 initialise dans une session la variable a avec la valeur 1 et appele la page 4 alors la page 4 connait la variable a.
Fichiers à consulter :
php_ses1.php page 1 "bête" qui initialise a sans session source php_ses2.php page 2 "bête" appelée sans session : a est inconnu source php_ses3.php page 3 initialisation de a avec session source php_ses4.php page 4 appelée avec session source Pour savoir si une variable est définie, on peut utiliser la fonction isset. Consulter la source de php_ses2.php pour voir son utilisation.
Pour conserver un tableau ou un objet, il faut utiliser serialize(). En voici un exemple : serialize.php
Pour faire un histogramme de pourcentages, une seule instruction suffit si on a tout préparé. Ainsi l'histogramme demandé correspond à l'URL http://forge.info.univ-angers.fr/~gh/jphistopct.php ?vdata=8_94_5_3_35&xmrks=gp_info_mkg_rh_stat&titr=REPARTITION%20DES%20CATEGORIES%20DE%20STAGES
Vous pouvez cliquer sur le lien précédent et modifier les paramètres pour voir dynamiquement le graphique évoluer. Mon script jphistopct est basé sur jpgraph.
Une traduction possible de codon2aa.pl est codons2aa.php. Si on l'applique au fichier mystere.txt on trouve PAPAMIMI en ligne 1 et MAMA en ligne 2.
Le fichier mygoogle.pl est une solution possible. Pour l'appel de google en ligne de commande, regardez goog.rex
Pour php, une solution est mygoogle.txt vérifiable ici.
Consulter personnes.php vérifiable ici.
Selon ses auteurs, Artichow est une librairie qui permet de créer simplement des graphiques avec PHP et GD. Consulter www.artichow.org et features pour en savoir plus. Problème : elle ne semble plus maintenue depuis 2006...
pChart est aussi une librairie graphique pour PHP ; on la trouve à l'adresse http://wiki.pchart.net/.
print_r signifie "print readable", le r signifie donc "lisible". Cela permet d'afficher la structure et le contenu d'un tableau, d'un objet. var_dump et var_export affichent aussi les contenus de variables.
Exemples : printr.php
La documentation officielle montre que var_dump est plus détaillée que print_r et que var_export fournit un code PHP utilisable.
Il est bien sur tout à fait possible d'écrire du Javascript via php. Voir par exemple phpjs.
Voir litdbf. Le seul problème est l'extension Dbase de PHP doit etre activée...
ERROR_REPORTING permet d'afficher ou de masquer des erreurs. Voir par exemple la page associée sur www.manuelphp.com ; ainsi en ligne de commande, avec error_reporting(E_ALL | E_STRICT | E_NOTICE ) ; $b = $a + 1 ; on obtient le message d'erreur "Notice: Undefined variable: a in erreurs.php on line 11. Si l'affichage des erreurs n'est pas demandé, avec $b = $a + 1 ; , PHP ne dit rien et met au final, 1 dans $b, ce qui n'était sans doute pas le but recherché.
Dans le même genre d'idées, mettre le symbole @ devant le symole d'une fonction évite d'afficher le message d'erreur en cas de problème. Voir le bas de la page exemples rapides pour des exemples d'utilisation de @.
L'affichage par défaut des erreurs n'utilise pas les encadrés oranges montrés. Cet affichage est géré par php5-xdebug qu'il faut installer. Attention : il faut aussi modifier php.ini (qui est dans /etc/php5/apache2/ pour Ubuntu) de façon à avoir html_errors=On et display_errors=On.
Cela doit sans doute provenir du serveur qui "balance" automatiquement un mauvais "Content-type". La solution en php consiste à forcer le "content-type" via la fonction header comme dans le fichier forceiso.php dont le code-source est ici. Sans php et sans toucher au serveur, il doit être possible de paramètrer le fichier htaccess pour associer un 'charset' à un type de fichier, par exemple utf pour .htm, iso pour .html mais attention aux effets de bord !
Pour les «tout-utf», il faut consulter forceutf.php dont le code-source est là.
On peut utiliser les fonctions PHP nommées show_source ou highlight_file comme par exemple ici. On peut également se contenter d'une solution entièrement en javascript avec un élément pre et un style brush une fois qu'on a chargé les fichiers js de SyntaxHighlighter ou utiliser des objets PHP via GeSHi (Generic Syntax Highlighter).
Voir les pages demandeUniprot.php et reponseUniprot.php dont le code-source est ici et là.
Transformations XSL utilisées : uniprot1.xsl et uniprot2.xsl sous-programme php : ; reponseUniprotFns.
La conclusion est que les expressions régulières sont plus puissantes que les fonctions de base sur les chaines de caractères mais que la transformation xsl est, au final, la plus concise et la plus facile à relire, à maintenir, meme si ce n'est pas toujours simple de la mettre au point.
Pour le passage d'un identifiant à l'autre, voir la page demande_bioinfo_id.php et reponse_bioinfo_id.php dont le code-source est ici et là.
Pour bien gérer les conversions d'identifiant, il faut se ramener au gi du NCBI car de nombreux sites savent l'utiliser.
Il est clair qu'à la lecture du code, la classe se nomme tdm et qu'elle utilise au moins quatre fonctions : titre, menu, afficheRubrique et rubriqueParNuméro sans que les paramètres soient facilement compréhensibles.
La classe tdm est définie à la fin du fichier std.php. On pourra aussi consulter demotdmobj.php dont le code-source est ici.
On pourra s'inspirer de alldsc.php ; l'exemple de fichier de sortie RTF (Word) nommé alldsc.rtf (source) et l'exemple de fichier de sortie CSV (Excel) nommé alldsc.csv (source) sont cliquables : alldsc.rtf et alldsc.csv.
Pour savoir sur quelle machine s'exécute le programme, il y a plusieurs solutions. La variable PHP_OS indique le système d'exploitation en court, la fonction php_uname() le renvoie en long et plus généralement, on peut exécuter une commande du système comme set. Ceci est surtout intéressant pour un programme qui s'exécute en ligne de commande. Lorsqu'un programme est exécuté via une page web, on dispose des variables d'environnement avec la fonction getenv(). Au passage, on pourra consulter la liste des constantes réservées. Un exemple de programme est quellemachine.php dont le code-source est ici.
Cours 6 : langage mysql et accès aux bases mysql via php (énoncé)
Pour obtenir les options de la ligne de commande, on tape mysql --help. Sous Unix, on peut également taper man mysql.
Avec mysql --help on obtient un texte comme celui-ci sous Linux ou comme celui-ci sous Windows avec EasyPhp alors qu'avec man mysql on obtient un texte comme celui-là.
L'option -E affiche tous les résultats en mode vertical, avec une indication de ligne de résultat.
Par exemple là ou en mode normal, une commande select affiche
+------+------+-----+------+------+------+------+ | NUM | SEXE | AGE | PROF | ETUD | REGI | USAG | +------+------+-----+------+------+------+------+ | M001 | 1 | 62 | 1 | 2 | 2 | 3 | | M002 | 0 | 60 | 9 | 3 | 4 | 1 | +------+------+-----+------+------+------+------+ 2 rows in set (0.00 sec)le mode -E affiche*************************** 1. row ******* NUM: M001 SEXE: 1 AGE: 62 PROF: 1 ETUD: 2 REGI: 2 USAG: 3 *************************** 2. row ******* NUM: M002 SEXE: 0 AGE: 60 PROF: 9 ETUD: 3 REGI: 4 USAG: 1 2 rows in set (0.00 sec)L'intérêt du mode -E réside dans le fait qu'un programme informatique peut plus facilement traiter les informations affichées. De plus, s'il y a beaucoup de champs(colonnes) alors on voit tout à l'écran sans problème de ligne découpée...
L'option -v affiche plus de détails qu'en mode normal et en particulier avec -v -v -v on obtient le rappel de l'instruction sql et une sortie bien formatée qu'on peut utiliser directement en impression.
Une fois sous mysql, on peut taper select version() ; pour avoir le numéro de version ; l'aide s'obtient avec help ; pour avoir la date et l'heure, on écrit respectivement select curdate() ; et select curtime() ; .
Pour connaitre toute la configuration, il faudrait utiliser un fichier de commandes mysql comme mysqlinfo.sql dont le contenu est :
SELECT USER(), CURRENT_USER(),CURDATE(),CURTIME(),VERSION() ; SHOW STATUS ; SHOW VARIABLES ; SHOW DATABASES ;Voici un exemple d'éxécution :
-------------- SELECT USER(), CURRENT_USER(),CURDATE(),CURTIME(),VERSION() -------------- +----------------+----------------+------------+-----------+--------------------+ | USER() | CURRENT_USER() | CURDATE() | CURTIME() | VERSION() | +----------------+----------------+------------+-----------+--------------------+ | root@localhost | root@localhost | 2011-02-05 | 16:43:16 | 5.1.41-3ubuntu12.9 | +----------------+----------------+------------+-----------+--------------------+ 1 row in set (0.00 sec) -------------- SHOW STATUS -------------- +-----------------------------------+----------+ | Variable_name | Value | +-----------------------------------+----------+ | Aborted_clients | 0 | | Aborted_connects | 3 | | Binlog_cache_disk_use | 0 | | Binlog_cache_use | 0 | | Bytes_received | 181 | | Bytes_sent | 431 | | Com_admin_commands | 0 | | Com_assign_to_keycache | 0 | | Com_alter_db | 0 | | Com_alter_db_upgrade | 0 | | Com_alter_event | 0 | | Com_alter_function | 0 | | Com_alter_procedure | 0 | | Com_alter_server | 0 | | Com_alter_table | 0 | | Com_alter_tablespace | 0 | | Com_analyze | 0 | | Com_backup_table | 0 | | Com_begin | 0 | | Com_binlog | 0 | | Com_call_procedure | 0 | | Com_change_db | 0 | | Com_change_master | 0 | | Com_check | 0 | | Com_checksum | 0 | | Com_commit | 0 | | Com_create_db | 0 | | Com_create_event | 0 | | Com_create_function | 0 | | Com_create_index | 0 | | Com_create_procedure | 0 | | Com_create_server | 0 | | Com_create_table | 0 | | Com_create_trigger | 0 | | Com_create_udf | 0 | | Com_create_user | 0 | | Com_create_view | 0 | | Com_dealloc_sql | 0 | | Com_delete | 0 | | Com_delete_multi | 0 | | Com_do | 0 | | Com_drop_db | 0 | | Com_drop_event | 0 | | Com_drop_function | 0 | | Com_drop_index | 0 | | Com_drop_procedure | 0 | | Com_drop_server | 0 | | Com_drop_table | 0 | | Com_drop_trigger | 0 | | Com_drop_user | 0 | | Com_drop_view | 0 | | Com_empty_query | 0 | | Com_execute_sql | 0 | | Com_flush | 0 | | Com_grant | 0 | | Com_ha_close | 0 | | Com_ha_open | 0 | | Com_ha_read | 0 | | Com_help | 0 | | Com_insert | 0 | | Com_insert_select | 0 | | Com_install_plugin | 0 | | Com_kill | 0 | | Com_load | 0 | | Com_load_master_data | 0 | | Com_load_master_table | 0 | | Com_lock_tables | 0 | | Com_optimize | 0 | | Com_preload_keys | 0 | | Com_prepare_sql | 0 | | Com_purge | 0 | | Com_purge_before_date | 0 | | Com_release_savepoint | 0 | | Com_rename_table | 0 | | Com_rename_user | 0 | | Com_repair | 0 | | Com_replace | 0 | | Com_replace_select | 0 | | Com_reset | 0 | | Com_restore_table | 0 | | Com_revoke | 0 | | Com_revoke_all | 0 | | Com_rollback | 0 | | Com_rollback_to_savepoint | 0 | | Com_savepoint | 0 | | Com_select | 2 | | Com_set_option | 0 | | Com_show_authors | 0 | | Com_show_binlog_events | 0 | | Com_show_binlogs | 0 | | Com_show_charsets | 0 | | Com_show_collations | 0 | | Com_show_column_types | 0 | | Com_show_contributors | 0 | | Com_show_create_db | 0 | | Com_show_create_event | 0 | | Com_show_create_func | 0 | | Com_show_create_proc | 0 | | Com_show_create_table | 0 | | Com_show_create_trigger | 0 | | Com_show_databases | 0 | | Com_show_engine_logs | 0 | | Com_show_engine_mutex | 0 | | Com_show_engine_status | 0 | | Com_show_events | 0 | | Com_show_errors | 0 | | Com_show_fields | 0 | | Com_show_function_status | 0 | | Com_show_grants | 0 | | Com_show_keys | 0 | | Com_show_master_status | 0 | | Com_show_new_master | 0 | | Com_show_open_tables | 0 | | Com_show_plugins | 0 | | Com_show_privileges | 0 | | Com_show_procedure_status | 0 | | Com_show_processlist | 0 | | Com_show_profile | 0 | | Com_show_profiles | 0 | | Com_show_slave_hosts | 0 | | Com_show_slave_status | 0 | | Com_show_status | 1 | | Com_show_storage_engines | 0 | | Com_show_table_status | 0 | | Com_show_tables | 0 | | Com_show_triggers | 0 | | Com_show_variables | 0 | | Com_show_warnings | 0 | | Com_slave_start | 0 | | Com_slave_stop | 0 | | Com_stmt_close | 0 | | Com_stmt_execute | 0 | | Com_stmt_fetch | 0 | | Com_stmt_prepare | 0 | | Com_stmt_reprepare | 0 | | Com_stmt_reset | 0 | | Com_stmt_send_long_data | 0 | | Com_truncate | 0 | | Com_uninstall_plugin | 0 | | Com_unlock_tables | 0 | | Com_update | 0 | | Com_update_multi | 0 | | Com_xa_commit | 0 | | Com_xa_end | 0 | | Com_xa_prepare | 0 | | Com_xa_recover | 0 | | Com_xa_rollback | 0 | | Com_xa_start | 0 | | Compression | OFF | | Connections | 105 | | Created_tmp_disk_tables | 0 | | Created_tmp_files | 5 | | Created_tmp_tables | 0 | | Delayed_errors | 0 | | Delayed_insert_threads | 0 | | Delayed_writes | 0 | | Flush_commands | 1 | | Handler_commit | 0 | | Handler_delete | 0 | | Handler_discover | 0 | | Handler_prepare | 0 | | Handler_read_first | 0 | | Handler_read_key | 0 | | Handler_read_next | 0 | | Handler_read_prev | 0 | | Handler_read_rnd | 0 | | Handler_read_rnd_next | 0 | | Handler_rollback | 0 | | Handler_savepoint | 0 | | Handler_savepoint_rollback | 0 | | Handler_update | 0 | | Handler_write | 0 | | Innodb_buffer_pool_pages_data | 19 | | Innodb_buffer_pool_pages_dirty | 0 | | Innodb_buffer_pool_pages_flushed | 0 | | Innodb_buffer_pool_pages_free | 493 | | Innodb_buffer_pool_pages_misc | 0 | | Innodb_buffer_pool_pages_total | 512 | | Innodb_buffer_pool_read_ahead_rnd | 1 | | Innodb_buffer_pool_read_ahead_seq | 0 | | Innodb_buffer_pool_read_requests | 77 | | Innodb_buffer_pool_reads | 12 | | Innodb_buffer_pool_wait_free | 0 | | Innodb_buffer_pool_write_requests | 0 | | Innodb_data_fsyncs | 3 | | Innodb_data_pending_fsyncs | 0 | | Innodb_data_pending_reads | 0 | | Innodb_data_pending_writes | 0 | | Innodb_data_read | 2494464 | | Innodb_data_reads | 25 | | Innodb_data_writes | 3 | | Innodb_data_written | 1536 | | Innodb_dblwr_pages_written | 0 | | Innodb_dblwr_writes | 0 | | Innodb_log_waits | 0 | | Innodb_log_write_requests | 0 | | Innodb_log_writes | 1 | | Innodb_os_log_fsyncs | 3 | | Innodb_os_log_pending_fsyncs | 0 | | Innodb_os_log_pending_writes | 0 | | Innodb_os_log_written | 512 | | Innodb_page_size | 16384 | | Innodb_pages_created | 0 | | Innodb_pages_read | 19 | | Innodb_pages_written | 0 | | Innodb_row_lock_current_waits | 0 | | Innodb_row_lock_time | 0 | | Innodb_row_lock_time_avg | 0 | | Innodb_row_lock_time_max | 0 | | Innodb_row_lock_waits | 0 | | Innodb_rows_deleted | 0 | | Innodb_rows_inserted | 0 | | Innodb_rows_read | 0 | | Innodb_rows_updated | 0 | | Key_blocks_not_flushed | 0 | | Key_blocks_unused | 13270 | | Key_blocks_used | 126 | | Key_read_requests | 31475 | | Key_reads | 126 | | Key_write_requests | 0 | | Key_writes | 0 | | Last_query_cost | 0.000000 | | Max_used_connections | 2 | | Not_flushed_delayed_rows | 0 | | Open_files | 122 | | Open_streams | 0 | | Open_table_definitions | 61 | | Open_tables | 61 | | Opened_files | 403 | | Opened_table_definitions | 0 | | Opened_tables | 0 | | Prepared_stmt_count | 0 | | Qcache_free_blocks | 1 | | Qcache_free_memory | 15806832 | | Qcache_hits | 219 | | Qcache_inserts | 823 | | Qcache_lowmem_prunes | 0 | | Qcache_not_cached | 164 | | Qcache_queries_in_cache | 823 | | Qcache_total_blocks | 1652 | | Queries | 1628 | | Questions | 3 | | Rpl_status | NULL | | Select_full_join | 0 | | Select_full_range_join | 0 | | Select_range | 0 | | Select_range_check | 0 | | Select_scan | 0 | | Slave_open_temp_tables | 0 | | Slave_retried_transactions | 0 | | Slave_running | OFF | | Slow_launch_threads | 0 | | Slow_queries | 0 | | Sort_merge_passes | 0 | | Sort_range | 0 | | Sort_rows | 0 | | Sort_scan | 0 | | Ssl_accept_renegotiates | 0 | | Ssl_accepts | 0 | | Ssl_callback_cache_hits | 0 | | Ssl_cipher | | | Ssl_cipher_list | | | Ssl_client_connects | 0 | | Ssl_connect_renegotiates | 0 | | Ssl_ctx_verify_depth | 0 | | Ssl_ctx_verify_mode | 0 | | Ssl_default_timeout | 0 | | Ssl_finished_accepts | 0 | | Ssl_finished_connects | 0 | | Ssl_session_cache_hits | 0 | | Ssl_session_cache_misses | 0 | | Ssl_session_cache_mode | NONE | | Ssl_session_cache_overflows | 0 | | Ssl_session_cache_size | 0 | | Ssl_session_cache_timeouts | 0 | | Ssl_sessions_reused | 0 | | Ssl_used_session_cache_entries | 0 | | Ssl_verify_depth | 0 | | Ssl_verify_mode | 0 | | Ssl_version | | | Table_locks_immediate | 2638 | | Table_locks_waited | 0 | | Tc_log_max_pages_used | 0 | | Tc_log_page_size | 0 | | Tc_log_page_waits | 0 | | Threads_cached | 0 | | Threads_connected | 2 | | Threads_created | 2 | | Threads_running | 1 | | Uptime | 20588 | | Uptime_since_flush_status | 20588 | +-----------------------------------+----------+ 291 rows in set (0.00 sec) -------------- SHOW VARIABLES -------------- +-----------------------------------------+-------------------------------------------------------------------------------------------+ | Variable_name | Value | +-----------------------------------------+-------------------------------------------------------------------------------------------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | | autocommit | ON | | automatic_sp_privileges | ON | | back_log | 50 | | basedir | /usr/ | | big_tables | OFF | | binlog_cache_size | 32768 | | binlog_format | STATEMENT | | bulk_insert_buffer_size | 8388608 | | character_set_client | latin1 | | character_set_connection | latin1 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | latin1 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | | collation_connection | latin1_swedish_ci | | collation_database | latin1_swedish_ci | | collation_server | latin1_swedish_ci | | completion_type | 0 | | concurrent_insert | 1 | | connect_timeout | 10 | | datadir | /var/lib/mysql/ | | date_format | %Y-%m-%d | | datetime_format | %Y-%m-%d %H:%i:%s | | default_week_format | 0 | | delay_key_write | ON | | delayed_insert_limit | 100 | | delayed_insert_timeout | 300 | | delayed_queue_size | 1000 | | div_precision_increment | 4 | | engine_condition_pushdown | ON | | error_count | 0 | | event_scheduler | OFF | | expire_logs_days | 10 | | flush | OFF | | flush_time | 0 | | foreign_key_checks | ON | | ft_boolean_syntax | + -><()~*:""&| | | ft_max_word_len | 84 | | ft_min_word_len | 4 | | ft_query_expansion_limit | 20 | | ft_stopword_file | (built-in) | | general_log | OFF | | general_log_file | /var/lib/mysql/ghchu.log | | group_concat_max_len | 1024 | | have_community_features | YES | | have_compress | YES | | have_crypt | YES | | have_csv | YES | | have_dynamic_loading | YES | | have_geometry | YES | | have_innodb | YES | | have_ndbcluster | NO | | have_openssl | DISABLED | | have_partitioning | YES | | have_query_cache | YES | | have_rtree_keys | YES | | have_ssl | DISABLED | | have_symlink | YES | | hostname | ghchu | | identity | 0 | | ignore_builtin_innodb | OFF | | init_connect | | | init_file | | | init_slave | | | innodb_adaptive_hash_index | ON | | innodb_additional_mem_pool_size | 1048576 | | innodb_autoextend_increment | 8 | | innodb_autoinc_lock_mode | 1 | | innodb_buffer_pool_size | 8388608 | | innodb_checksums | ON | | innodb_commit_concurrency | 0 | | innodb_concurrency_tickets | 500 | | innodb_data_file_path | ibdata1:10M:autoextend | | innodb_data_home_dir | | | innodb_doublewrite | ON | | innodb_fast_shutdown | 1 | | innodb_file_io_threads | 4 | | innodb_file_per_table | OFF | | innodb_flush_log_at_trx_commit | 1 | | innodb_flush_method | | | innodb_force_recovery | 0 | | innodb_lock_wait_timeout | 50 | | innodb_locks_unsafe_for_binlog | OFF | | innodb_log_buffer_size | 1048576 | | innodb_log_file_size | 5242880 | | innodb_log_files_in_group | 2 | | innodb_log_group_home_dir | ./ | | innodb_max_dirty_pages_pct | 90 | | innodb_max_purge_lag | 0 | | innodb_mirrored_log_groups | 1 | | innodb_open_files | 300 | | innodb_rollback_on_timeout | OFF | | innodb_stats_on_metadata | ON | | innodb_support_xa | ON | | innodb_sync_spin_loops | 20 | | innodb_table_locks | ON | | innodb_thread_concurrency | 8 | | innodb_thread_sleep_delay | 10000 | | innodb_use_legacy_cardinality_algorithm | ON | | insert_id | 0 | | interactive_timeout | 28800 | | join_buffer_size | 131072 | | keep_files_on_create | OFF | | key_buffer_size | 16777216 | | key_cache_age_threshold | 300 | | key_cache_block_size | 1024 | | key_cache_division_limit | 100 | | language | /usr/share/mysql/english/ | | large_files_support | ON | | large_page_size | 0 | | large_pages | OFF | | last_insert_id | 0 | | lc_time_names | en_US | | license | GPL | | local_infile | ON | | locked_in_memory | OFF | | log | OFF | | log_bin | OFF | | log_bin_trust_function_creators | OFF | | log_bin_trust_routine_creators | OFF | | log_error | /var/log/mysql/error.log | | log_output | FILE | | log_queries_not_using_indexes | OFF | | log_slave_updates | OFF | | log_slow_queries | OFF | | log_warnings | 1 | | long_query_time | 10.000000 | | low_priority_updates | OFF | | lower_case_file_system | OFF | | lower_case_table_names | 0 | | max_allowed_packet | 16777216 | | max_binlog_cache_size | 18446744073709547520 | | max_binlog_size | 104857600 | | max_connect_errors | 10 | | max_connections | 151 | | max_delayed_threads | 20 | | max_error_count | 64 | | max_heap_table_size | 16777216 | | max_insert_delayed_threads | 20 | | max_join_size | 18446744073709551615 | | max_length_for_sort_data | 1024 | | max_prepared_stmt_count | 16382 | | max_relay_log_size | 0 | | max_seeks_for_key | 18446744073709551615 | | max_sort_length | 1024 | | max_sp_recursion_depth | 0 | | max_tmp_tables | 32 | | max_user_connections | 0 | | max_write_lock_count | 18446744073709551615 | | min_examined_row_limit | 0 | | multi_range_count | 256 | | myisam_data_pointer_size | 6 | | myisam_max_sort_file_size | 9223372036853727232 | | myisam_recover_options | BACKUP | | myisam_repair_threads | 1 | | myisam_sort_buffer_size | 8388608 | | myisam_stats_method | nulls_unequal | | myisam_use_mmap | OFF | | net_buffer_length | 16384 | | net_read_timeout | 30 | | net_retry_count | 10 | | net_write_timeout | 60 | | new | OFF | | old | OFF | | old_alter_table | OFF | | old_passwords | OFF | | open_files_limit | 1024 | | optimizer_prune_level | 1 | | optimizer_search_depth | 62 | | optimizer_switch | index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on | | pid_file | /var/lib/mysql/ghchu.pid | | plugin_dir | /usr/lib/mysql/plugin | | port | 3306 | | preload_buffer_size | 32768 | | profiling | OFF | | profiling_history_size | 15 | | protocol_version | 10 | | pseudo_thread_id | 104 | | query_alloc_block_size | 8192 | | query_cache_limit | 1048576 | | query_cache_min_res_unit | 4096 | | query_cache_size | 16777216 | | query_cache_type | ON | | query_cache_wlock_invalidate | OFF | | query_prealloc_size | 8192 | | rand_seed1 | | | rand_seed2 | | | range_alloc_block_size | 4096 | | read_buffer_size | 131072 | | read_only | OFF | | read_rnd_buffer_size | 262144 | | relay_log | | | relay_log_index | | | relay_log_info_file | relay-log.info | | relay_log_purge | ON | | relay_log_space_limit | 0 | | report_host | | | report_password | | | report_port | 3306 | | report_user | | | rpl_recovery_rank | 0 | | secure_auth | OFF | | secure_file_priv | | | server_id | 0 | | skip_external_locking | ON | | skip_networking | OFF | | skip_show_database | OFF | | slave_compressed_protocol | OFF | | slave_exec_mode | STRICT | | slave_load_tmpdir | /tmp | | slave_net_timeout | 3600 | | slave_skip_errors | OFF | | slave_transaction_retries | 10 | | slow_launch_time | 2 | | slow_query_log | OFF | | slow_query_log_file | /var/lib/mysql/ghchu-slow.log | | socket | /var/run/mysqld/mysqld.sock | | sort_buffer_size | 2097144 | | sql_auto_is_null | ON | | sql_big_selects | ON | | sql_big_tables | OFF | | sql_buffer_result | OFF | | sql_log_bin | ON | | sql_log_off | OFF | | sql_log_update | ON | | sql_low_priority_updates | OFF | | sql_max_join_size | 18446744073709551615 | | sql_mode | | | sql_notes | ON | | sql_quote_show_create | ON | | sql_safe_updates | OFF | | sql_select_limit | 18446744073709551615 | | sql_slave_skip_counter | | | sql_warnings | OFF | | ssl_ca | | | ssl_capath | | | ssl_cert | | | ssl_cipher | | | ssl_key | | | storage_engine | MyISAM | | sync_binlog | 0 | | sync_frm | ON | | system_time_zone | CET | | table_definition_cache | 256 | | table_lock_wait_timeout | 50 | | table_open_cache | 64 | | table_type | MyISAM | | thread_cache_size | 8 | | thread_handling | one-thread-per-connection | | thread_stack | 196608 | | time_format | %H:%i:%s | | time_zone | SYSTEM | | timed_mutexes | OFF | | timestamp | 1296920596 | | tmp_table_size | 16777216 | | tmpdir | /tmp | | transaction_alloc_block_size | 8192 | | transaction_prealloc_size | 4096 | | tx_isolation | REPEATABLE-READ | | unique_checks | ON | | updatable_views_with_limit | YES | | version | 5.1.41-3ubuntu12.9 | | version_comment | (Ubuntu) | | version_compile_machine | x86_64 | | version_compile_os | debian-linux-gnu | | wait_timeout | 28800 | | warning_count | 0 | +-----------------------------------------+-------------------------------------------------------------------------------------------+ 271 rows in set (0.00 sec) -------------- SHOW DATABASES -------------- +--------------------+ | Database | +--------------------+ | information_schema | | LEA | | mysql | | statdata | +--------------------+ 4 rows in set (0.00 sec) ByeIl est très simple d'interfacer perl et mysql car perl dispose d'un module DBI qui interface toutes les implémentations classiques des bases de données dont mySQL ; lire le fichier perl_mysql.pdf pour plus d'informations. Vous pouvez lire ici un exemple de fichier perl qui utilise DBI.
Pour exécuter une liste de commandes SQL mises dans un fichier, on peut soit utiliser la redirection d'entrée soit (à partir de la version 4.) utiliser la commande source dont le raccourci est \. Ainsi pour le fichier prog.mysql on peut soit écrire
mysql < prog.mysqlsoit charger mysql puis tapersource prog.mysqlou\. prog.mysql
Il faut transférer la structure et les données via mysqldump puis tout réinsérer sur le portable, soit par exemple pour la table elf :
mysqldump ... test.elf > elf.mysql # [sur forge] export vers fichier texte # transfert sur le portable via ftp ou sftp de elf.mysql mysql ... < elf.mysql # [sur le portable] importAttention, sur le portable, il faudra sans doute écriremysql_connnect("localhost","root","")au lieu demysql_connnect("forge","anonymous","anonymous")La commande mysqldump fournit le code-source pour la recréation de la table et du remplissage avec les données, soit ici : elf.mysql. Vous trouverez dans le fichier lestables.zip le code MySql pour recréer les tables.Consulter la fin du tuteur MySql.
Pour PHP 5 avec le module mysql, voir le fichier combienPhp5.php dont l'exécution est ici.
Pour PHP 7 avec le module mysqli la solution est presque la même voir le fichier combienMysqli.php dont l'exécution est ici.
Enfin, pour PHP 7 et PDO la solution est dans le fichier combienPDO.php dont l'exécution est ici.
Consulter ronfle30a39 pour la source ; l'url ronfle30a39.php en fournit l'exécution. On pourra comparer avec ronflemieux.php dont l'exécution est ici.
Il faut bien sur utiliser SQL pour les tris. SQL est prévu et donc optimisé pour cela. De plus avec PHP, on accède aux résultats par tableau. Un tri multicritères est donc compliqué à écrire en PHP, mais pas en SQL.
Voici une solution possible (non conceptuelle) : (code-source complet ; éxécution)
$nc1 = "idmedecin" ; $nc2 = "med_initiales" ; $que = "select $nc1, $nc2 from medecins order by $nc1 " ; $res = mysql_query($que) ; echo "<select name='num_med'>\n" ; while ($ldr=mysql_fetch_array($res)) { $num = $ldr[$nc1] ; $ini = $ldr[$nc2] ; echo "<option value=\"$num\"> $ini </option>\n" ; } ; # fin de tant que echo "</select>" ;Remarque : on peut aussi considérer qu'il s'agit de la partie "amont" de l'exercice sur les initiales de médecin (énoncé ici). Auquel cas on peut se contenter de remplir correctement la variable $ldi, soit le code suivant pour remplacer la boucle tant_que précédente :$ldi = "" ; while ($ldr=mysql_fetch_array($res)) { $ldi .= " ".$ldr[$nc1]." " ; } ; # fin de tant queLa solution "conceptuelle naive" consiste à passer par nos fonctions de gestion des formulaires. Le code correspondant est medinibd.php.
La solution "conceptuelle propre" consiste à passer par notre fonction listeSelectFromTxt(). Le code correspondant est medecins1.php.
Pour un exemple plus réaliste (on connait plutot le nom du médecin que ses initiales), il y a même une fonction conceptuelle nommée listeSelectFromChampMySql(). Le code correspondant est medecins2.php.
A l'aide de show databases, show tables et describe, tout est possible !
Voici un formulaire qui le prouve : f_dscbaz.php qui utilise comme action dscbaz.php dont le code-source est ici sachant qu'on utilise aussi le programme listebases.php et le programme listetables.php. Le code-source du formulaire, non conceptuel (snif !) est là.
Vous pouvez récupérer une archive de ces programmes.
Le site officiel http://www.mysql.com contient tout ce qu'il faut comme documentation.
Pour une carte de référence rapide, on peut lire php4ref.pdf qui provient du site
http://www.digilife.be/quickreferences/quickrefs.htm Pour une documentation en français, nous rappelons qu'il faut utiliser les documents du site
http://www.nexen.net/docs/mysql/
et en particulier la version en ligne annotée :http://www.nexen.net/docs/mysql/annotee/manuel_tocd.php
Voici le texte du formulaire f_sout.txt et son exploitation via envoisout.txt : on a mis XXX, YYY, ZZZ etc. en nom et place des vrais noms de table, base... de même, le mot de passe pour la remise à zéro de la base n'est pas celui actuellement utilisé ; envoisout.txt est un "vieux" texte, non concetuel à réécrire via montresource.php?nomfic=std.php...
Il suffit de rajouter target="_blank" dans la balise <form> Ce "target" peut aussi être utilisé avec href. Attention : en XHTML, c'est interdit !
Consulter categstages.php dont le code source lisible est ici.
Voir histo.php dont le code-source est ici qui utilise histos.php.
Si on stockait les mots de passe, il suffirait de pirater la base de données pour les trouver. On utilise donc une fonction injective (au sens des mathématiques) pour coder le mot de passe. On stocke le codage md5 du mot de passe. Il suffit alors de comparer le codage md5 de l'entrée dans le formulaire avec la valeur stockée pour valider l'utilisateur... On trouvera dans le fichier loginpasswd.php un exemple d'utilisation.
Vous pouvez consulter tplongprogs.zip et aussi tplong/ pour une démonstration des programmes dont la liste des services et la liste du personnel.
Cours 7 : html, xhtml et xml (énoncé)
Cette question n'aucun sens. On peut discuter de document "bien formé" dans l'absolu (balises ouvertes bien fermées, par exemple) mais pour parler de validité, il faut indiquer par rapport à quelle grammaire. Pour la grammaire transitionnelle, le fragment de code est valide. Pour XHTML strict, il n'est pas valide car il mélange le fond et la forme : l'attribut background est donc interdit. On peut utiliser au choix soit un style à la volée comme : <body style='background-image:url(beige.jpg)'> mais un "bon" concepteur préferera un style mis dans un fichier css, soit par exemple : <body class='fond_beige'> où fond_beige est par exemple défini par body.fond_beige { background-image:url("beige.jpg") }.
Le document xmp.htm s'affiche correctement avec un navigateur comme Netscape ou Internet Explorer. Toutefois, il contient de petites erreurs. Voici par exemple ce que dit weblint :
ligne 5 The HTML spec. recommends the TITLE be no longer than 64 characters. ligne 18 : empty container element <P>. ligne 23 : value for attribute HREF (http://forge.info.univ-angers.fr/~gh/) of element A should be quoted (i.e. HREF="http://forge.info.univ-angers.fr/~gh/") ligne 23 : IMG does not have ALT text defined. ligne 29 : empty container element <P>.Commençons par gérer les petites erreurs sans conséquence.
L'erreur en ligne 5 peut se corriger en raccourcissant le titre au texte "Page à tester".
On peut sans doute supprimer les balises <P> des lignes 18 et 29 pour ne plus avoir de paragraphes vides.
Au niveau de la ligne 23, il faut impérativement ajouter des guillemets pour référencer l'URL ; pour l'image, on peut indiquer en mode ALT qu'il s'agit du retour à la page principale soit finalement le texte correct : consulter xmp2.htm dont la source est xmp2_htm.txt
Si maintenant on se préoccupe de HTML 4 et de XHTML, à l'aide du site
http://validator.w3.org/ on voit apparaitre une erreur grave : il n'y a pas de balise DOCTYPE comme première balise. Si on met
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">comme nouvelle première ligne du document, alors le document est valide pour la spécification "HTML 4.01 Transitional". On pourra le vérifier en essayant de vérifier l'URL
http://forge.info.univ-angers.fr/~gh/internet/xmp3.htmPar contre si on veut un "vrai" document XHTML Strict, alors il reste du travail à faire comme on peut s'en rendre compte en vérifiant l'URL
http://forge.info.univ-angers.fr/~gh/internet/xmp4.htmEnfin, il est clair que xmp.htm n'est pas un document XHTML car sinon comme tout document XML, il commencerait par
<xml...Et ce n'est pas non plus un document XML car de nombreuses balises ne sont pas fermées, comme par exemple les <p>. De plus les "entités" comme et à ne sont pas définies, pas plus que le codage (qui est sans doute ici ISO-8859 comme pour tout "bon français qui se respecte"). A ce propos, signalons qu'il est certainement peu cohérent de coder avec des accents comme dans "pensé" et de coder avec des entités comme dans "après". On consultera donc xmp4.htm comme document valide en XML/XHTMl Strict.
Les options de la commande rxp sont obtenues par rxp --help à savoir :
usage: rxp [-abemnNsStvVx] [-o b|0|1|2|3] [-c encoding] [-u base_uri] [url]Vous pouvez consulter ici la page de manuel correspondante. Pour n'afficher que les erreurs, on utilise -s comme silent et pour valider on utilise -V (à ne pas confondre avec -v comme verbose).
Si on tape xmllint sans option, on voit la liste des options à savoir :
Usage : xmllint [options] XMLfiles ... Parse the XML files and output the result of the parsing --version : display the version of the XML library used --debug : dump a debug tree of the in-memory document --shell : run a navigating shell --debugent : debug the entities defined in the document --copy : used to test the internal copy implementation --recover : output what was parsable on broken XML documents --noent : substitute entity references by their value --noout : don't output the result tree --nonet : refuse to fetch DTDs or entities over network --htmlout : output results as HTML --nowrap : do not put HTML doc wrapper --valid : validate the document in addition to std well-formed check --postvalid : do a posteriori validation, i.e after parsing --dtdvalid URL : do a posteriori validation against a given DTD --dtdvalidfpi FPI : same but name the DTD with a Public Identifier --timing : print some timings --output file or -o file: save to a given file --repeat : repeat 100 times, for timing or profiling --insert : ad-hoc test for valid insertions --compress : turn on gzip compression of output --html : use the HTML parser --xmlout : force to use the XML serializer when using --html --push : use the push mode of the parser --memory : parse from memory --nowarning : do not emit warnings from parser/validator --noblanks : drop (ignorable?) blanks spaces --nocdata : replace cdata section with text nodes --format : reformat/reindent the input --encode encoding : output in the given encoding --dropdtd : remove the DOCTYPE of the input docs --nsclean : remove redundant namespace declarations --testIO : test user I/O support --catalogs : use SGML catalogs from $SGML_CATALOG_FILES otherwise XML Catalogs starting from file:///etc/xml/catalog are activated by default --nocatalogs: deactivate all catalogs --auto : generate a small doc on the fly --xinclude : do XInclude processing --loaddtd : fetch external DTD --dtdattr : loaddtd + populate the tree with inherited attributes --stream : use the streaming interface to process very large files --walker : create a reader and walk though the resulting doc --pattern pattern_value : test the pattern support --chkregister : verify the node registration code --relaxng schema : do RelaxNG validation against the schema --schema schema : do validation against the WXS schema Libxml project home page: http://xmlsoft.org/ To report bugs or get some help check: http://xmlsoft.org/bugs.htmlUne page de manuel pour xmllint est ici.Pour n'afficher que les erreurs, rien à faire, c'est ce qui se passe par défaut.Par contre pour ne pas voir le texte, il faut utiliser l'option --noout et pour valider, il faut utiliser l'option --valid.
Le fichier elfdix.xml est bien formé ; on peut le vérifier en tapant
rxp elfdix.xmlou en tapantxmllint elfdix.xmlou même simplement en essayant de le charger dans un navigateur...Par contre savoir s'il est valide est une question qui n'a aucun sens : on doit dire valide par rapport à une grammaire (DTD ou XSD) et aucune grammaire n'est fournie ici.
Le fichier vins.xml n'est pas bien formé car il manque > à la balise LIGNEDATA de la ligne 10 (CHMP soit champagne). Si on rajoute > alors le fichier est bien formé.
Malheureusement même une fois corrigé si on lui ajoute
<!DOCTYPE DOSSIER SYSTEM "statdata.dtd">ce fichier n'est pas valide pour la grammaire statdata.dtd ; voici la raison donnée par rxp
rxp -V -s vins_ok.xml Warning: Content model for DSC does not allow it to end here in unnamed entity at line 9 char 7 of file:/vins_ok.xmlet la raison donnée par xmllint
xmllint --noout --valid vins_ok.xml vins_ok.xml:9: element DSC: validity error : Element DSC content does not follow the DTD, expecting (NOM , LDSC , NATURE , DATE), got (NOM LDSC NATURE )ce qui signifie que la balise DSC est incorrecte (car il lui manque pour cette grammaire DTD la balise DATE).Il n'est pas valide non plus pour la grammaire statdata.xsd car si on met comme entête pour le fichier modifié
<DOSSIER xsi:noNamespaceSchemaLocation="statdata.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" >alors notre programme perl nommé testevs.pl présenté dans notre tuteur XML renvoie comme erreur :sirius> perl testevs.pl vins.xml statdata.xsd le document nommé vins4xsd.xml n'est pas valide pour son schéma : Inside element 'DOSSIER', element 'DSC' does not match content model '(TITRE,DSC,NOMSCOL,LIGNEDATA+)'.De même, notre programme java nommé testevs.java présenté dans notre tuteur XML renvoie comme erreur :deneb> java testevs vins.xml statdata.xsd Le document n'est pas valide pour le schéma fourni : true cvc-complex-type.2.4.a: Invalid content starting with element 'DSC'. The content must match '(("":TITRE),("":DSC),("":NOMSCOL),("":LIGNEDATA){1-UNBOUNDED})'.ce qui signifie que la balise DSC est incorrecte (car il lui manque pour cette grammaire XSD la balise TITRE).
Si on applique la transformation heros.xsl au fichier XML Films.xml on obtient les titres des films, chaque titre étant mis dans une balise paragraphe (ce qui pour l'instant ne sert à rien).
Voici le texte de la transformation :
<?xml version="1.0" encoding="ISO-8859-1"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html" encoding="ISO-8859-1" /> <xsl:template match="/"> <xsl:apply-templates select="//TITRE" /> </xsl:template> <xsl:template match="TITRE"> <p><xsl:value-of select="." /></p> </xsl:template> </xsl:stylesheet>Et le début du fichier des films :
<?xml version="1.0" encoding="ISO-8859-1"?> <FILMS> <FILM Annee='1958'> <TITRE>Vertigo</TITRE> <GENRE>Drame</GENRE><PAYS>USA</PAYS><MES idref="3"></MES> <ROLES> <ROLE><PRENOM>James</PRENOM><NOM>Stewart</NOM> <INTITULE>John Ferguson</INTITULE></ROLE><ROLE><PRENOM>Kim</PRENOM> <NOM>Novak</NOM> <INTITULE>Madeleine Elster</INTITULE></ROLE></ROLES> <RESUME>Scottie Ferguson, ancien inspecteur de police, est sujet au vertige depuis qu'il a vu mourir son collègue. Elster, son ami, le charge de surveiller sa femme, Madeleine, ayant des tendances suicidaires. Amoureux de la jeune femme Scottie ne remarque pas le piège qui se trame autour de lui et dont il va être la victime... </RESUME> </FILM> <FILM Annee='1979'> <TITRE>Alien</TITRE> <GENRE>Science-fiction</GENRE><PAYS>USA</PAYS><MES idref="4"></MES> <ROLES> <ROLE><PRENOM>Sigourney</PRENOM><NOM>Weaver</NOM> <INTITULE>Ripley</INTITULE></ROLE></ROLES> <RESUME>Près d'un vaisseau spatial échoué sur une lointaine planète, des Terriens en mission découvrent de bien étranges "oeufs". Ils en ramènent un à bord, ignorant qu'ils viennent d'introduire parmi eux un huitième passager particulièrement féroce et meurtrier. </RESUME> </FILM> ...Voici le début de l'affichage correspondant à la transformation :
<p>Vertigo</p> <p>Alien</p> <p>Titanic</p> <p>Sacrifice</p> <p>Volte/Face</p> <p>Sleepy Hollow</p> <p>American Beauty</p> <p>Impitoyable</p> ...Si maintenant on utilise la transformation titres.xsl comme feuille de style alors on obtient un vrai document HTML comme titres.xml converti à la volée par le navigateur. Pour utiliser cette feuille de style, il suffit de mettre comme début de document xml :
<?xml version="1.0" encoding="ISO-8859-1"?> <?xml-stylesheet type="text/xsl" href="titres.xsl"?> <FILMS> <FILM Annee='1958'> <TITRE>Vertigo</TITRE> <GENRE>Drame</GENRE><PAYS>USA</PAYS><MES idref="3"></MES> <ROLES> ...
On peut écrire de nombreux fichiers XML pour un stage selon que l'on veut utiliser des éléments imbriqués ou des couples (attribut,valeur). Un fichier "purs éléments" ressemblerait à
<stage> <sujet> </sujet> <an> </an> <categorie> </categorie> <stagiaire> <nom> </nom> <prenom> </prenom> <numtel> </numtel> <adr> </adr> <mail> </mail> </stagiaire> <entreprise> <nom> </nom> <mds> </mds> <!-- maitre de stage --> <adr> <rueetc> </rueetc> <codepost> </codepost> <fincp> </fincp> <!-- fin code postal --> </adr> <telent> </telent> <!-- telephone entreprise --> <telmds> </telmds> <!-- telephone mds --> <telfax> </telfax> <!-- numero de fax --> <mailmds> </mailmds> </entreprise> </stage>Un fichier XML qui serait "tous couples (attribut,valeur)" ressemblerait plutot à
<stage sujet="" an="" categorie=""> <stagiaire nom="" prenom="" numtel="" adr="" mail="" /> <entreprise nom="" mds="" adr_rueetc="" adr_codepost="" adr_fincp="" telent="" telmds="" telfax="" mailmds="" /> </stage>Et bien sur des panachés entre ces deux fichiers extrêmes sont possibles. La bonne solution (si tant est qu'il n'y en ait qu'une seule) doit se trouver en regardant ce qu'on veut faire ensuite comme traitements.
Si on exécute en ligne de commande
mysql --xml ... --database statdata < stagesMaitrise.mysql > stagesMaitrise.xmloù stagesMaitrise.mysql contient seulement select * from stagesMaitrise alors mysql produit automatiquement le fichier stagesMaitrise.xml ce qui montre que mysql connait en standard xml... mais pas les accents !
On pourra consulter :
stage1a_xml.txt le stage 1 en xml solution 1 stage1b_xml.txt le stage 1 en xml solution 2 stage2a_xml.txt le stage 2 en xml solution 1 stage2b_xml.txt le stage 2 en xml solution 2 Il est déconseillé d'essayer d'écrire les grammaires DTD et XSD correspondantes à la main car des outils logiciels comme XMLSPY ou des outils en ligne commme la page Web
http://www.hitsw.com/xml_utilites/ le font automatiquement et bien mieux que nous, et qui plus est, sans erreur dans les fichiers-grammaires.
On pourra comparer les grammaires stagea_xmlspy.dtd et stagea_xmlspy.xsd produites par XMLSPY pour le modèle a avec les grammaires stagea_xmlutil.dtd et stagea_xmlutil.xsd crées par la page Web citée pour le modèle a.
De la même façon, on comparera les grammaires stageb_xmlspy.dtd et stageb_xmlspy.xsd produites par XMLSPY pour le modèle b avec les grammaires stageb_xmlutil.dtd et stageb_xmlutil.xsd crées par la page Web citée pour le même modèle.
Pour la liste des stages, on peut par exemple à l'aide d'un programme mettre les fichiers bout à bout à l'intérieur d'une balise <stages> (avec un "s" en fin de balise) soit le fichier
<?xml version="1.0" encoding="ISO-8859-1" ?> <stages> <stage> ... ici le contenu de stage1.xml </stage> <stage> ... ici le contenu de stage2.xml </stage> </stages>Une autre solution, que nous préférons, consiste par programme à définir une entité pour chaque fichier stage et à la nommer dans la balise <stages> (avec un "s" en fin de balise) soit le fichier
<?xml version="1.0" encoding="ISO-8859-1" ?> <!DOCTYPE ENCYCLOPEDIE [ <!ENTITY stg1b SYSTEM "stage1.xml"> <!ENTITY stg2b SYSTEM "stage2.xml"> ]> <stages> &stg1b; &stg2b; </stages>Voir stages.xsl qui contient
Exemple d'utilisation : nbstages.xml (afficher la source pour avoir une surprise !)
Voir extr_stages.php exécutable ici.
La commande xpath permet de tester quels noeuds de l'arbre XML sont obtenus par filtre. On pourra lire par exemple à ce sujet le fameux xpath tutorial.Voici -- non commentées à l'écrit -- les réponses aux questions d'interrogations de noeuds :
xpath -e "//TITRE" films.xml xpath -e "//ROLE/NOM" films.xml xpath -e "//FILMS/FILM[@Annee=1990]/TITRE" films.xml xpath -e "/FILMS/ARTISTE[@id=/FILMS/FILM[TITRE='Alien']/MES/@idref]/ACTNOM films.xmlNous avons "honteusement" pris ces exemples sur la page de Cedric au Cnam :
http://cedric.cnam.fr/vertigo/Cours
Oui, un script php peut appeler un programme perl avec shell_exec si le serveur Web est configuré pour autoriser l'exécution de programmes et si les chemins d'accès (path) sont corrects. Consulter le fichier vers.php et sa source.
Voici un fichier xml2dar.xsl possible :
<?xml version="1.0" encoding="ISO-8859-1"?> <!-- xml2dar.xsl : n'affiche que les données --> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="text" encoding="ISO-8859-1" /> <xsl:variable name="sautdeLigne"> <xsl:text> </xsl:text> </xsl:variable> <xsl:template match="/"> <xsl:apply-templates select="//NOMSCOL|//LIGNEDATA" /> </xsl:template> <xsl:template match="NOMSCOL"> <xsl:value-of select="concat(.,$sautdeLigne)" /> </xsl:template> <xsl:template match="LIGNEDATA"> <xsl:value-of select="concat(.,$sautdeLigne)" /> </xsl:template> </xsl:stylesheet>On pourra le comparer à xml2dar2_trim.xsl.On exécute bien sûr cette transformation avec notre programme exsl.java.
A savoir, on écrit en ligne de commande pour l'appliquer au fichier elfdix.xml:deneb> java exsl elfdix.xml xml2dar.xslToutefois, comme il s'agit d'un programme Java, il faut peut-être rajouter un classpath comme par exemple :deneb> java -classpath .:/shared/lib/xalan.jar exsl elfdix.xml xml2dar.xsl
Voici le jeu de piste pour les 12 réponses aux 12 questions :
Source des fichiers utilisés :
countp.xsl lsagents.xsl ltagents.xsl
counts.xsl lsserv.xsl ltserv.xsl
PHP supporte nativement JSON ; voir par exemple http://fr.php.net/json.
Le programme repx.php utilise DOM pour créer le texte XML suivant (formatage adapté à la compréhension) :
<?xml version="1.0"?> <conv> <pouces>-1</pouces> <cm>-1</cm> </conv>


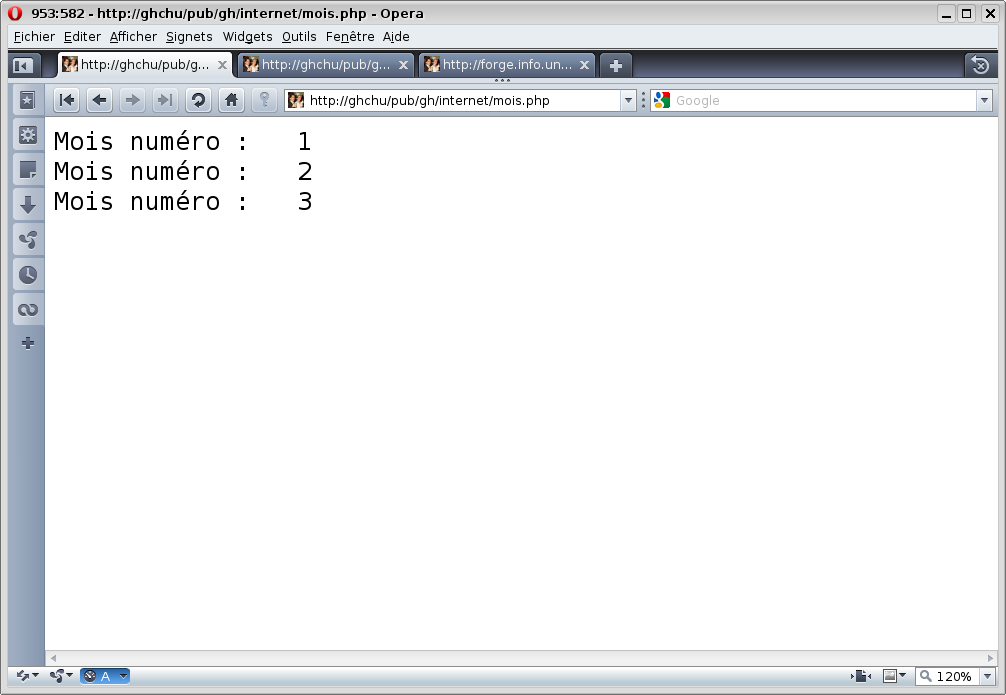
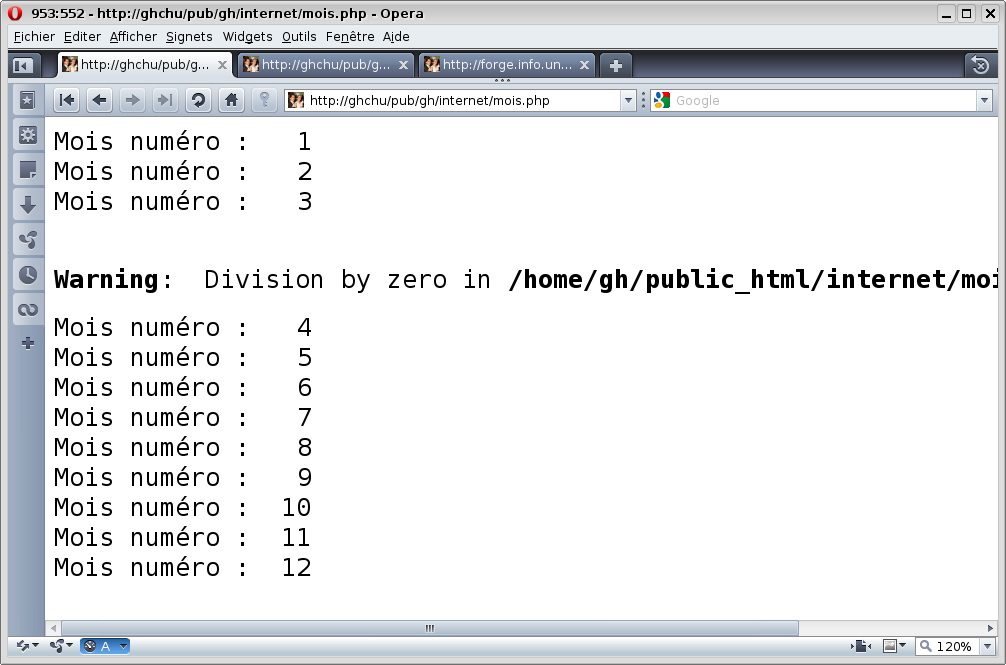
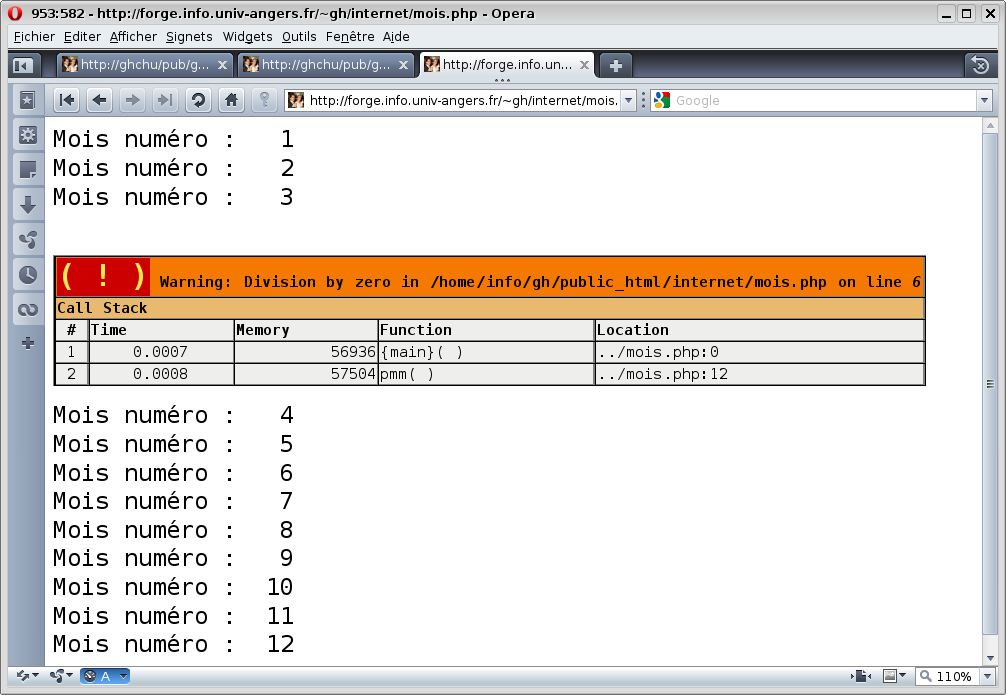
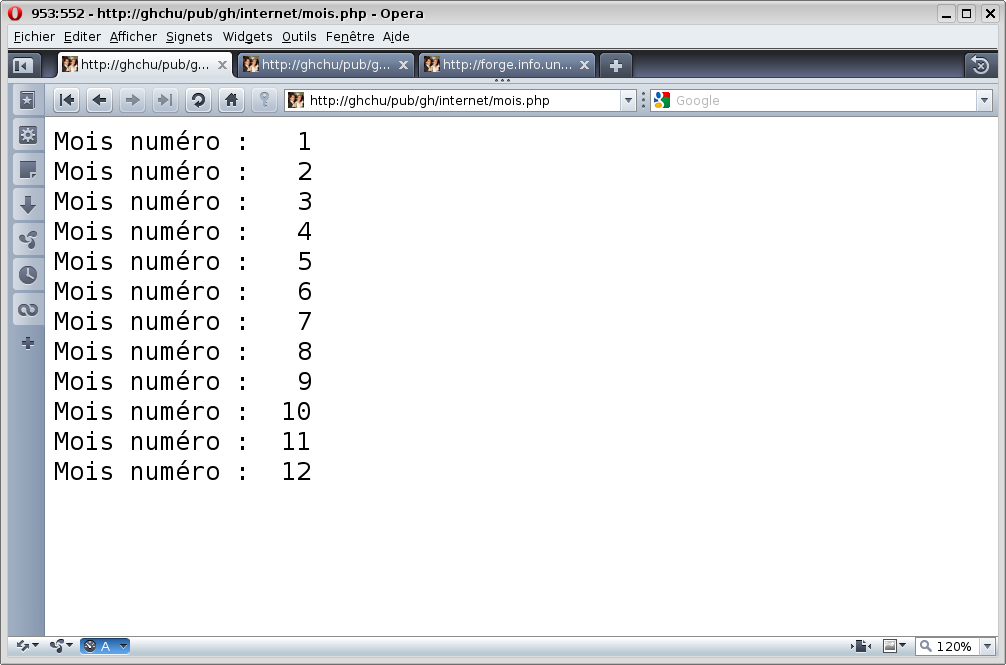
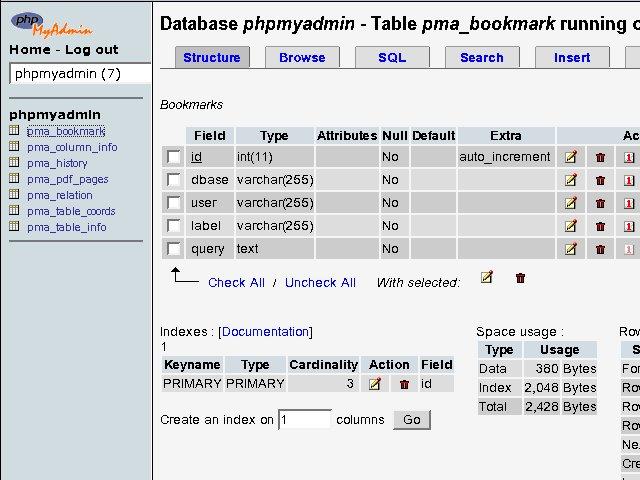
{kind=link}
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)