![]()
![]()
Quelques choix de modélisations mathématiques,statistiques et informatiquesdans le domaine de la santé et du végétalgilles.hunault "at" univ-angers.fr
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Quelques choix de modélisations mathématiques,
statistiques et informatiques
dans le domaine de la santé et du végétal
gilles.hunault "at" univ-angers.fr
Site compagnon de l'exposé Choix mathématiques... dans le cadre de la Journée Mathématiques-Sciences du Vivant organisée par l'Agence Lebesgue et dont le programme est ici.

Table des matières cliquable
2. Présentation de ces retours d'expérience
3. Quelle classification ascendante hiérarchique utiliser ?
4. Comment garantir la fiabilité en régression logistique ?
5. Quelle caractérisation spécifique minimale conserver ?
6. Ne parlons pas de l'estimateur d'Aalen-Johansen !
7. Kullback-Leibler ou Bhattacharyya ?
8. Comment choisir un modèle de prédiction à trois classes ?
9. Distances : euclidiennes ou non euclidiennes ?
1. Remerciements aphabétiques
C.H.U : Sandrine BERTRAIS, Jérôme BOURSIER, Paul CALES. Laboratoire HIFIH.
Centre Paul PAPIN : Michelle BOIDRON-CELLE, Erick GAMELIN. ICO.
I.N.R.A. Angers : Matthieu BARRET, Tristan BOUREAU, Louis GARDAN.
L.E.R.I.A. / Département informatique : Jacques BOYER, Benoit DA MOTA, Frédéric LARDEUX, David LESAINT, Frédéric SAUBION. Laboratoire LERIA.
Doctorants devenus docteurs : Fabien CHHEL, Céline ROUSSEAU, Sory TRAORE.
+ les technicien(ne)s, ingénieur(e)s et autres personnels B.I.A.T.S.S.
2. Présentation de ces retours d'expérience
- décrire le problème en termes métier,
- situer la problématique mathématique, statistique ou informatique,
- esquisser les choix effectués et leur rationnel.
3. Quelle classification ascendante hiérarchique utiliser ?
Position du problème (1980) :
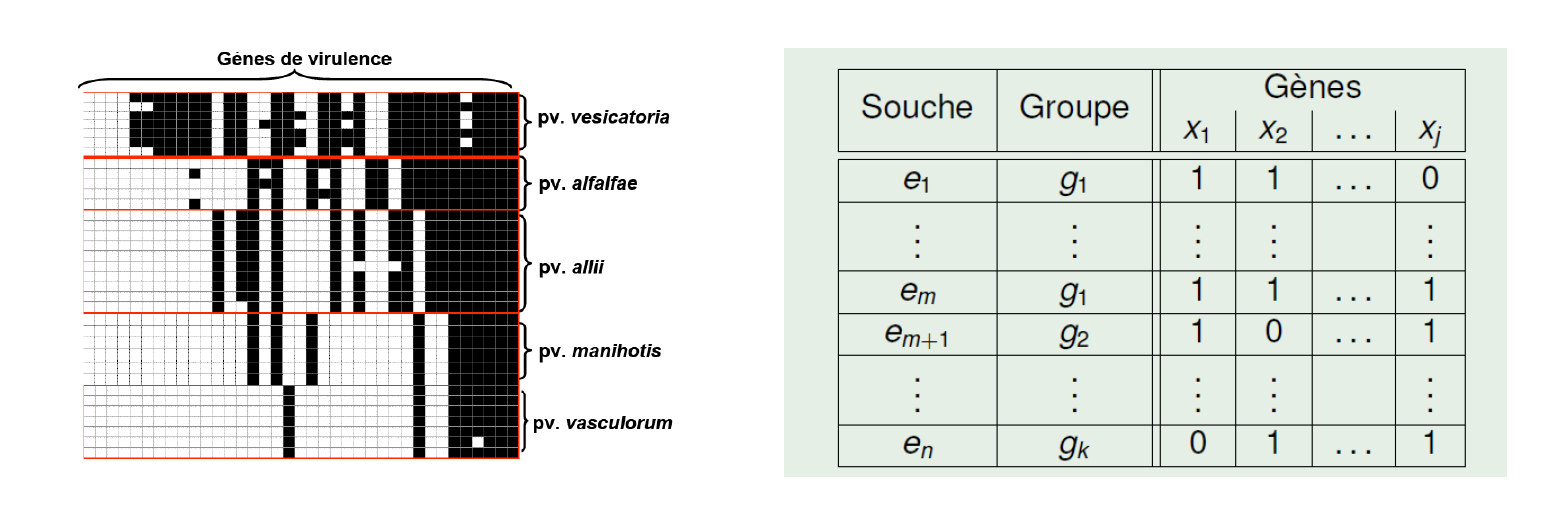
On veut réaliser une classification non supervisée de souches bactériennes phytopathogènes de Pseudomonas en fonction de caractéristiques phénotypiques binaires ou ternaires.
Taille des données : disons quelques centaines de lignes, quelques dizaines de colonnes. Les données sont sur cartes perforées à Angers. Le programme est exécuté à Marseille. On obtient le listing du dendrogramme en 3 mois après correction des erreurs de saisie.
Comment faire mieux ?
Choix mathématiques et informatiques :
Effectuer des traitements en local, écrire le programme de classification/clustering (mais dans quel langage de programmation ?). Continuer à réaliser des classifications hiérarchiques non supervisées plutôt que des simples partitionnements et, parmi ces méthodes, retenir des classifications ascendantes plutôt que descendantes afin de rester cohérent avec les précédentes classifications. Utiliser une distance « standard » pour la matrice d'entrée. Choisir un critère d'agrégation adapté aux données phénotypiques de souches bactériennes.
Rappel du principe des méthodes CAH
A partir d'une matrice de distances entre éléments isolés
- on choisit deux éléments qu'on fusionne en un nouvel élément,
- on calcule la distance entre les anciens éléments et le nouveau,
- on supprime les deux anciens éléments choisis,
- on recommence jusqu'à avoir regroupé tout le monde.
Liste des choix en CAH dans les années 80 :
- choix de la distance initiale ou "coût", "score"...
binaire jaccard, russel-rao, simpson, sokal... comptage czekanowski, clark, kulczynski... info hamming, wagner, levenstein, édition... autre dice, tanimoto... - choix du critère de sélection ou indice d'agrégation "linkage" simple ou complet, "pair group"... divergence, inertie...
- choix de la formule de recalcul des distances min, max, moyenne, pondérée, ultramétrique...
Quelques formules de recalcul des distances

Choix statistiques et réalisations dans les années 80 :
Paramètre Choix Distance initiale Jaccard-Sneath Critère d'agrégation Lien mininimal Formule de recalcul UPGMA Implémentations en FORTRAN puis en PASCAL, en Dbase VII Windows et enfin en PHP.
La distance de Jaccard et Sneath (induite par l'indice de similarité éponyme) est bien adaptée aux problèmes de taxonomie bactérienne sur données binaires.
Le lien minimal est un choix raisonnable car c'est le critère d'agrégation du programme à Marseille.
La formule de recalcul UPGMA était le choix conseillé à l'époque par la communauté taxonomique européenne.
Et si c'était à refaire en 2017 :
La liste des méthodes s'est allongée ward, single, complete, average, mcquitty, median, centroid... donc encore des choix à faire.
La liste des distances s'est allongée donc encore des choix et des comparaisons à faire.
Par contre il n'y aurait plus de de programmation importante à réaliser : les logiciels scientifiques et statistiques -- R, Python, SAS, SPSS, Statistica, Matlab, Scilab -- ont tous aujourd'hui des modules, des packages, des procédures de calculs de distances, de classification.
...encore faut-il savoir utiliser ces logiciels et connaitre les modules.
Liste des choix de méthodes possibles en 2017 :
Méthodes_non_supervisées Méthodes_supervisées classifications hiérarchiques, réseau de neurones, k-moyennes, centres mobiles, algorithmes génétiques, nuées dynamiques, algorithmes de colonies, de fourmis, cartes auto-organisatrices... algorithmes auto-adaptatifs... 51 indices de dissimilarités pour données binaires en 2017 via Todeschini et al. :

a désigne le nombre de 1 communs aux deux colonnes, d désigne le nombre de 0 communs aux deux colonnes, c et d correspondent aux occurences de discordance (valeur 1 pour une colonne et 0 pour l'autre).
Quelques distances possibles en 2017 via R :
Via la fonction dist() du package stats pour le logiciel R : euclidean maximum manhattan canberra binary minkowski.
Via la fonction vegdist() du package vegan pour le logiciel R :
bray kulczynski jaccard gower altGower morisita
horn mountford raup binomial chao mahalanobis
Attention au logiciel R car en septembre 2017 :
- environ 14 000 packages,
- soit à peu près 1 million 925 mille fonctions.
Consulter Rdocumentation/trends pour la valeur exacte du nombre de packages.
Attention aussi aux langages et aux interfaces d'application :
Quel langage ? R ou Python ? Quelle version ? (2.7.14 vs 3.3.7 vs 3.6.2) ?
Quelle utilisation en 2017 via :
- une application ?
- une page Web comme Cabiq/Classification ?
- un script, disons en R comme xmp2.r ?
...quid des données ternaires ?
Au passage, thèse GH (1983) en statistiques mathématiques à Paris VI, direction J. P. Benzécri :
Classification hiérarchique de variables qualitatives.
4. Comment garantir la fiabilité en régression logistique ?
Position du problème de recherche clinique
On s'intéresse au diagnostic (pas au pronostic) de fibrose hépatique à l'aide de marqueurs biologiques (age, sexe, bilan sanguin...). La référence ou « gold standard » -- bien que partiellement fausse -- se nomme stade METAVIR F et s'exprime en 5 classes progressives F=0 à F=4.
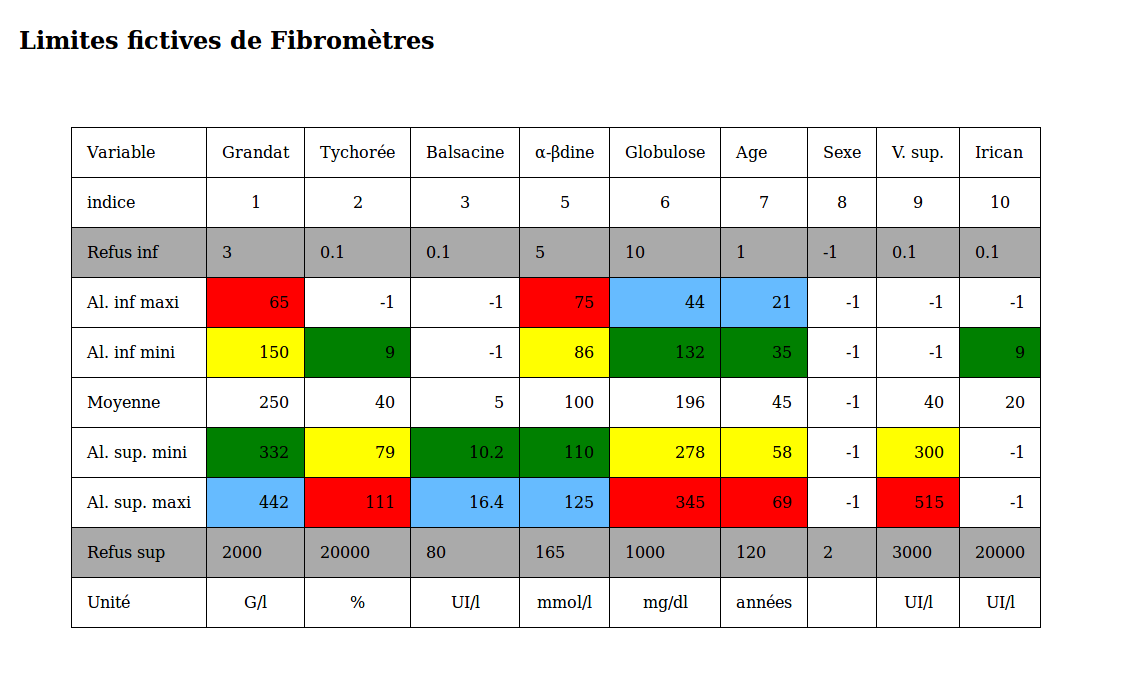
On dispose d'images de biopsies hépatiques avec des programmes d'analyse d'images pour définir/vérifier les stades METAVIR. On dispose de deux cibles binaires privilégiées avec nécessité de traiter, nommées fibrose avancée F<=2 et cirrhose hépatique F=4. On a déjà sélectionné des modèles de régression logistique binaire à 4, 5, 6 ou 7 variables pour ces cibles suivant l'étiologie (alcool, virus, stéatopathie) via leur performance (AUROC, AIC, YOUDEN...).
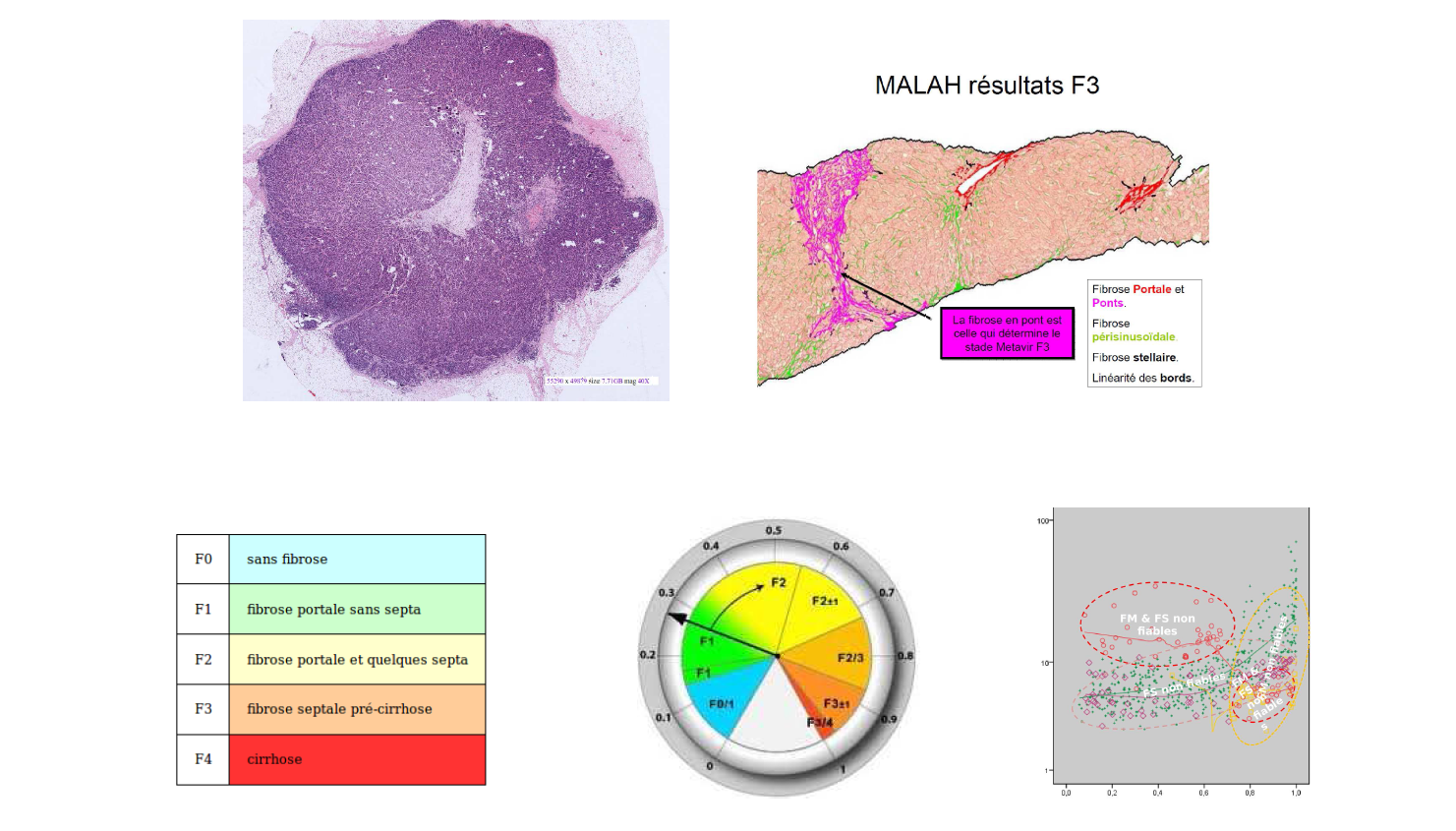
Comment minimiser les faux-négatifs, les faux-positifs et quantifier la fiabilité des résultats pour des scores exprimés sur les 5 classes Fi ?
Choix mathématiques, statistiques et informatiques (1)
Puisque la sélection de variables a déjà été faite, il faut essayer de :
- comprendre du point de vue médical d'où viennent les faux-négatifs, les faux-positifs.
- trouver mathématiquement comment prendre en compte ces faux-négatifs et ces faux-positifs.
- réussir à transcrire la fiabilité des résultats au praticien et au patient.
L'idée de base a consisté à
- encadrer le comportement des régressions logistiques en fonction de seuils d'alertes (débordements) pour les marqueurs.
- comparer les scores issus des différentes régressions logistiques.
Mais hélas...
il y a beaucoup de cas à modéliser car on peut avoir une, deux...n alertes simultanées ;
le prescripteur peut disqualifier un marqueur (sauf l'age) pour des raisons de traitements en cours ;
l'urée comme seule alerte peut être un facteur de confusion ;
certains marqueurs sont biologiquement dépendants...
Choix mathématiques, statistiques et informatiques (2)
sur les milliers de cas possibles, des cas standards d'alertes similaires (comme 2R1J) doivent mener aux mêmes calculs ;
la comparaison des RLB doit pouvoir se faire soit en supprimant la variable soit en la remplaçant par la normale clinique ;
il faut régler des seuils de distance entre RLB pour les comparer ;
il faut un indice de fiabilité du résultat exprimé en % ;
il faut injecter à chaque niveau de décision des compétences médicales.
Conclusion
Un simple programme de calcul statistiques ne suffit pas, il faut développer un calculateur/système expert (en chainage avant), avec environ 250 règles de décision et avec une base de données de cas typiques.
Historique des réalisations
1998 premiers essais de modèles de régressions logistiques binaires multiples (premier test publié en 1997) 2002 premières modélisations performantes de régressions logistiques binaires multiples 2004 dépot du premier brevet associé, création de la startup BioLiveScale 2006 premier Fibromètre payant 2011
- première vente de licence - recommandation nationale (HAS) d'utiliser les tests sanguins non invasifs en première intention dont les Fibromètres
- remboursement par la sécurité sociale d'un Fibromètre par an Problèmes rencontrés
- réussir à bien définir les échantillons de modélisation et de validation (interne, externe, indépendante)
- garantir que les modèles s'appliquent effectivement au tout-venant et pas seulement aux patients (malades) du CHU
- tester et montrer que des méthodes plus techniques comme les régressions ordinales, polytomiques ne font pas mieux que des RLB
- définir un indicateur de fiabilité basé sur une dispersion relative invariante par translation qui sera inclus dans la feuille de résultats
- programmer les choix, les faire valider par les cliniciens et trouver comment améliorer les performances jusqu'à un niveau acceptable pour une utilisation internationale.
5. Quelle caractérisation spécifique minimale conserver ?

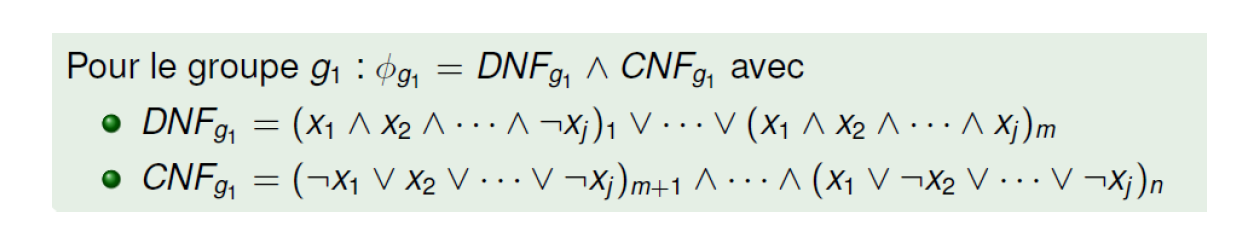
Dialogue de sourds (1)
[B] J'ai des groupes de lignes de pathovars de Xanthomonas avec des colonnes de présence/absence de gènes de virulence et je cherche à savoir quelles combinaisons de colonnes caractérisent les groupes à 100 %. [M] C'est quoi Xanthomonas ? et pathovars ? [B] 1. des bactéries pathogènes (plus graves que Pseudomonas) ; 2. une commodité de classement intraspécifique. [M] OK, je vous fais une régression logistique multinomiale ou une analyse discriminante... [B] C'est quoi une analyse discriminante ? [M] Une méthode de modélisation/prédiction statistique qui renvoie des probabilités d'appartenance à chaque classe. Où est le problème ?
Attention : on ne veut pas un prédicteur de classes pour chaque ligne mais des descripteurs minimaux et spécifiques (exacts à 100 % pour chaque groupe, à 0 % pour les autres groupes).
Une solution statistique classique de sélection de variables est-elle adaptée ?
NON Aucune méthode statistique ne garantit de prédiction exacte à 100 %.
Peut-on essayer d'emboiter des combinaisons de variables avec des coefficients de capacité à diagnostiquer des classes avec des critères d'entropie, d'information au sens de Shannon, de tester des fréquences d'appartenance a priori et a posteriori ?
NON. Là encore, aucune méthode ne garantit de prédiction exacte à 100 %.
Quelques questions à se poser pour résoudre le problème
est-on sûr d'avoir forcément au moins une solution ?
que déduire s'il n'y a pas de solution ?
et au contraire, que faire s'il y a plus d'une solution ?
comment faire si les statistiques n'ont pas de méthode adaptée pour résoudre ce problème ?
au fait, s'agit-il d'un problème connu et classique ?
Quelques éléments de réponses après de nombreux essais
le problème posé n'est pas «simple» car il est équivalent à un problème NP-complet Σ2p de classe W2 de minimisation d'expressions logiques DNF (formes normales disjonctives) ;
cependant en pratique, sur les données fournies par l'INRA on "trouve" souvent des solutions par tatonnement ou par programme avec 5 ou 6 colonnes impliquées ;
il est très simple de construire un jeu de données sans solution à cause d'au moins une contradiction logique ;
une approche informatique combinatoire semble pouvoir trouver ces solutions en un temps raisonnable (stage de M2).
Un «solveur» comme solution
Une combinaison de colonnes en 0/1 peut être assimilée à une formule logique avec 0=FAUX et 1=VRAI.
Une solution exhaustive en disjonction de conjonctions existe mais elle est assimilable à du sur-apprentissage : le groupe Gi, c'est l'élément ei1 ou ei2 ou ei3... ; l'élément eij, c'est sa valeur en colonne 1 et sa valeur en colonne 2 et ...
Il faut donc inventer un solveur pour réduire, simplifier ces formules et trouver des caractérisations à la fois spécifiques et minimales.
Mais pour quelle minimalité ?
De quelle minimalité s'agit-il ?
Solution minimale en longueur par groupe (6 colonnes en tout)
Groupe Formule Longueur Taille Nb. Colonnes Grp1 C1=1 et C2=1 et C3=0 3 3 3 Grp2 C4=1 et C5=0 et C6=0 3 3 3 Solution minimale en nombre de colonnes (4 colonnes en tout)
Groupe Formule Longueur Taille Nb. Colonnes Grp1 C1=1 et C2=1 et C4=0 et C5=1 4 4 4 Grp2 C1=0 et (C2=0 ou C4=1) et C5=0 3 4 4 Stratégie de résolution retenue
le solveur est capable d'exhiber une solution ou toutes les solutions spécifiques et minimales en colonnes ou en longueur s'il n'y a pas de contradictions dans les données ;
si les données comportent peu de contradictions : création et analyse de sous-ensembles de données ;
au cas où il y a dans les données de nombreuses contradictions : rejet des données (manque de puissance d'expression).
Réalisations effectuées sur 3 ans
un solveur efficace avec de nombreuses options de calcul pour les données de l'INRA (thèse de F. Chhel) ;
une interface Web avec plusieurs formats d'entrée/sortie (dont Excel et XML) ;
plus d'un quinzaine de caractérisations INRA réelles obtenues ;
4 articles et 2 posters en biologie et en informatique ;
dépot d'un brevet et réalisation d'une puce avec la société DIAG-GENE ;
une étude informatique plus poussée en cours sur le problème de caractérisation multiple.
6. Ne parlons pas de l'estimateur d'Aalen-Johansen !
Le problème posé :
dans un cadre d'évaluation médico-économique, il s'agit d'une analyse de type coût-efficacité ;
on doit étudier des données incomplètes «censurées» (patients décédés, perdus de vue, sortis de l'étude...) ;
la censure, ici à droite de type I (fixe ou aléatoire), est informative, ce qui rend les modèles de Kaplan-Meier des données de survie seules inadaptés ;
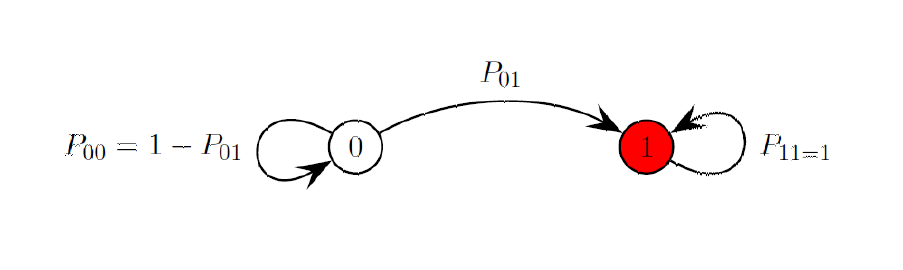
on doit l'appliquer au bénéfice potentiel d'un dépistage pré-thérapeutique des toxicités induites par le 5-FU (fluorouracile) dans le cas du traitement du cancer colo-rectal ;
on doit prendre en compte le fait qu'il s'agit d'un modèle multi-états à risques compétitifs et récurrents ;
la survenue des toxicités et les coût accumulés sont modélisées par des processus stochastiques particuliers nommés processus markoviens à temps continu.
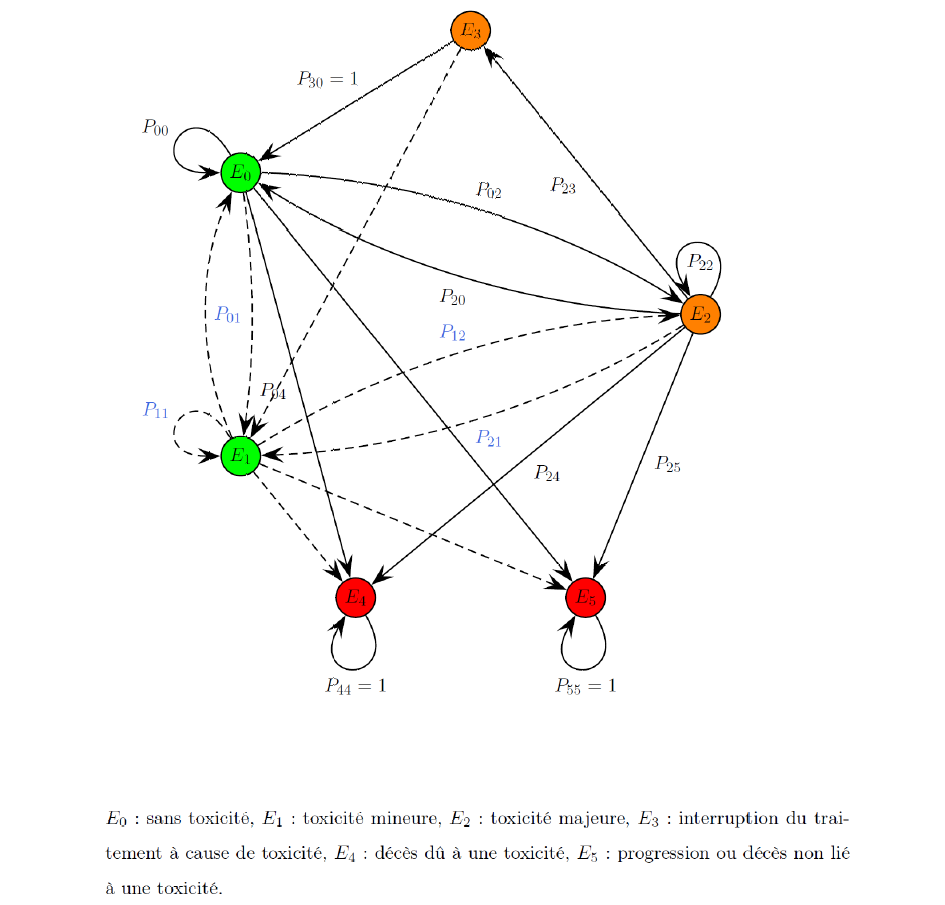
Contexte de l'étude :
On estimait à 37 413 nouveaux cas par an et 16 865 décès par an de cancers colorectaux, en 2005 en France selon l'INCa et l'InVS. Malgré le développement de nouvelles molécules comme l'Irinotécan et l'Oxaliplatine, le 5-fluorouracile (5-FU) reste le traitement de référence en chimiothérapie dans ce type de cancer. Si l'efficacité du 5-FU est définitivement admise tant en terme de réponse qu'en terme d'allongement de la durée de survie des patients (cf. MAPoon1, MAPoon2, Erlichman), il n'en demeure pas moins qu'il engendre encore des toxicités très sévères chez certains patients (altération de la qualité de vie, toxicités mortelles). On estime entre 0,3 % et 1,2 % la fréquence des décès liés au traitement selon les protocoles habituels à base de 5-FU et entre 25 % et 30 % la fréquence des toxicités graves (grade III-IV OMS), (cf. essai MOSAIC, essai NSABP C-07).
En outre, 14 % des patients arrêtent le traitement à cause d'une toxicité (Mosaic). Enfin, les toxicités mobilisent d'importantes ressources : Tsalic et al., 2003 ont observé 13 % d'hospitalisations à cause de toxicités dues au 5-FU dans une étude prospective portant sur 243 patients traités par un protocole standard à base de 5-FU. Le coût par patient à 10 mois est estimé à 2793 € pour une incidence des toxicités majeures à 31 % (Delea et al., 2002) aux USA.
Réalisations
Dans le cadre de la thèse de S. Traoré, deux estimateurs non-paramétriques du coût médical cumulé ont été proposés et étudiés théoriquement (biais, consistance, vitesse de convergence et normalité asymptotique). Ces estimateurs ont ensuite été comparés aux méthodes existantes sur des données simulées au niveau du biais, des probabilités de couverture de la moyenne théorique (par un intervalle de confiance défini selon une loi normale) avant d'être appliqués à des données réelles (dont celle du Centre Paul PAPIN).

La thèse a permis de tester et de valider deux hypothèses :
- Hypothèse 1 (médicale) :
Le dépistage pré-thérapeutique réduit l'incidence des toxicités liées au 5-FU, évite les décès dus au 5-FU sans diminuer le délai avant progression tumorale.
- Hypothèse 2 (économique) :
Le coût supplémentaire que ce dépistage génère est inférieur au coût de prise en charge des toxicités qu'il permet d'éviter.
Applications aux données réelles


La cohorte A correspond au dépistage pré-thérapeutique du CPP. Constituée entre septembre 1993 et août 2007, elle met en jeu 856 patients.

La cohorte B est celle de l'essai C-96 (André et al.). Elle repose sur une la stratégie « standard » qui consiste à administrer les doses traditionnelles de 5-FU selon la posologie du protocole utilisé. 886 patients avaient été inclus entre juillet 1996 et novembre 1999. Tous les patients de cette population étaient en traitement adjuvant. Cette cohorte constitue le groupe de témoins de l'évaluation.
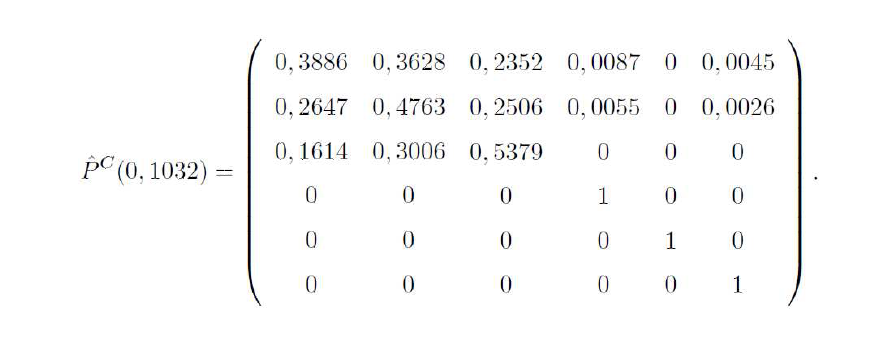
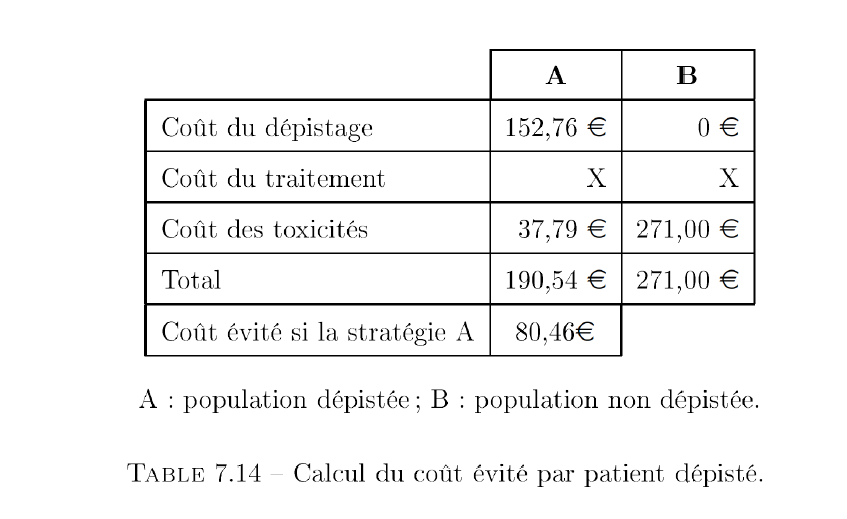
Interprétation de cette matrice des probabilités de transitions estimées par l'estimateur d'Aalen-Johansen :
sachant qu'un patient quelconque se trouve dans l'état 1 (absence de toxicité) pour un coût médical accumulé de 0 €, la probabilité qu'il se trouve dans l'état 3 (toxicité majeure) après un coût médical accumulé de 1032 € est 0,2352.
Conclusions

Des résultats à discuter et conforter.
Des calculs en R, mais pas de package.
Pas de relation avec PRISM (probabilistic model checker).
7. Kullback-Leibler ou Bhattacharyya ?
De quoi s'agit-il ?
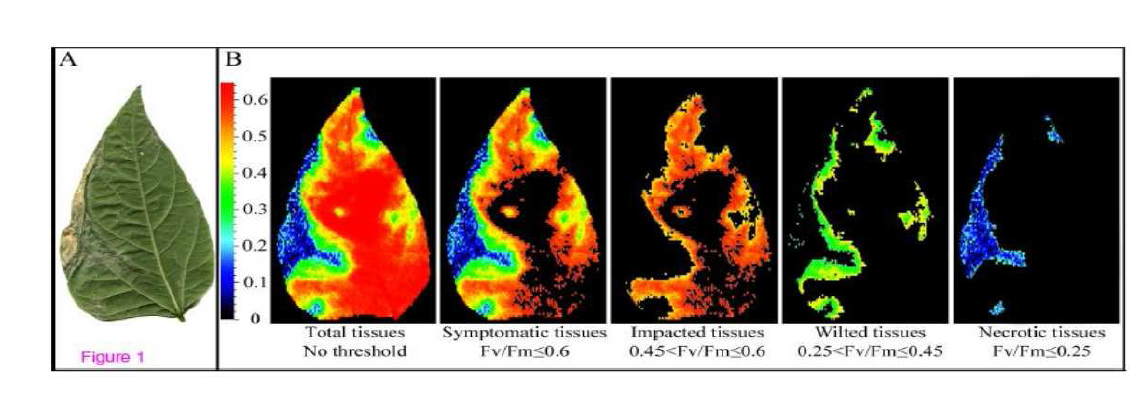
Dans un contexte d'analyse d'images de fluorescence de chlorophylle produites par l'imageur FluoCam7, on voudrait comparer des images de feuilles saines et de feuilles infectées.
Ces images sont vues au travers des histogrammes donc on doit comparer des histogrammes.
Quelles distances existent entre histogrammes ?
Y a-t-il des test statistiques pour comparer des histogrammes ?
Au passage : faut-il normaliser les histogrammes avant comparaison ?
Quelles comparaisons d'histogrammes ?
On sait classiquement comparer des moyennes, des médianes, des variances, des distributions, mais des histogrammes ? Dans la littérature, on trouve des indices de dissimilarité, des distances comme
la distance QF ou bin-similarity Quadratic-Form distance,
la distance EMD ou Earth Mover's Distance,
la distance du χ2 entre histogrammes,
la distance induite par la divergence de Kullback-Leibler,
Mais attention, il faut parfois entrer la distribution et la fonction utilisée calcule elle-même les histogrammes ; dans certains cas, il faut le même nombre de classes, et/ou avec les mêmes intervalles de boites...
Un choix pragmatique
Pour l'instant (novembre 2017) aucun choix n'a été défini, des analyses sont en cours pour tester les différentes distances et ce qu'elles montrent...
si quelqu'un dans la salle peut nous aider, il/elle sera le/la bienvenu/e...
8. Comment choisir un modèle de prédiction à trois classes ?
On s'intéresse à nouveau au diagnostic de fibrose hépatique.

Les données fournies proviennent de deux centres, Angers (n=522) et Bordeaux (n=532), avec des caractéristiques différentes.
Pour chaque patient, on dispose de 10 mesures d'élastométrie et d'un diagnostic d'expert en trois classes de niveau de fibrose : FL=1, FL=2 et FL=3 (possiblement FL=1 vs le reste et FL=3 vs le reste).
Question 1 : Comment modéliser et reproduire l'avis de l'expert ?
Question 2 : Combien de mesures faut-il utiliser ?
Remarque : prendre une mesure dure environ 3 minutes.
Quelques pistes de réflexion
Il s'agit de classification supervisée.
Il faut certainement synthétiser les données, mais quel(s) indicateurs ou combinaison d'indicateurs sont pertinents ?
- moyenne, médiane, minimum, maximum, autre quantile, autre indicateur de tendance centrale ?
- écart-type, iqr, mad, autre indicateur de dispersion ?
- cdv, iqrr, madr, autre indicateur de dispersion relative ?
Après une revue de plusieurs centaines de modèles
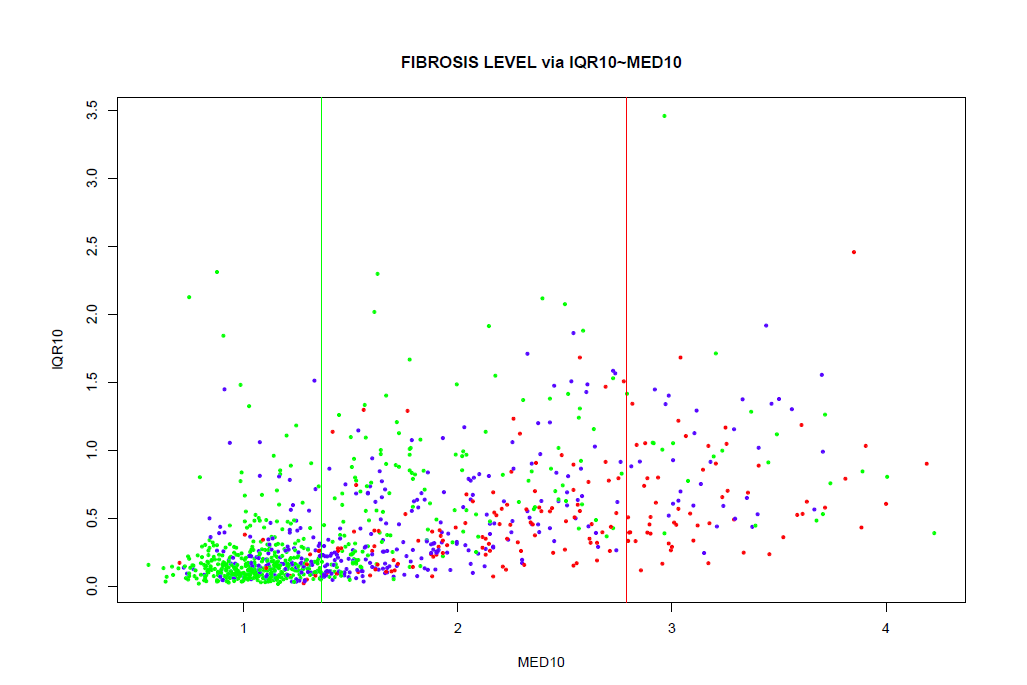
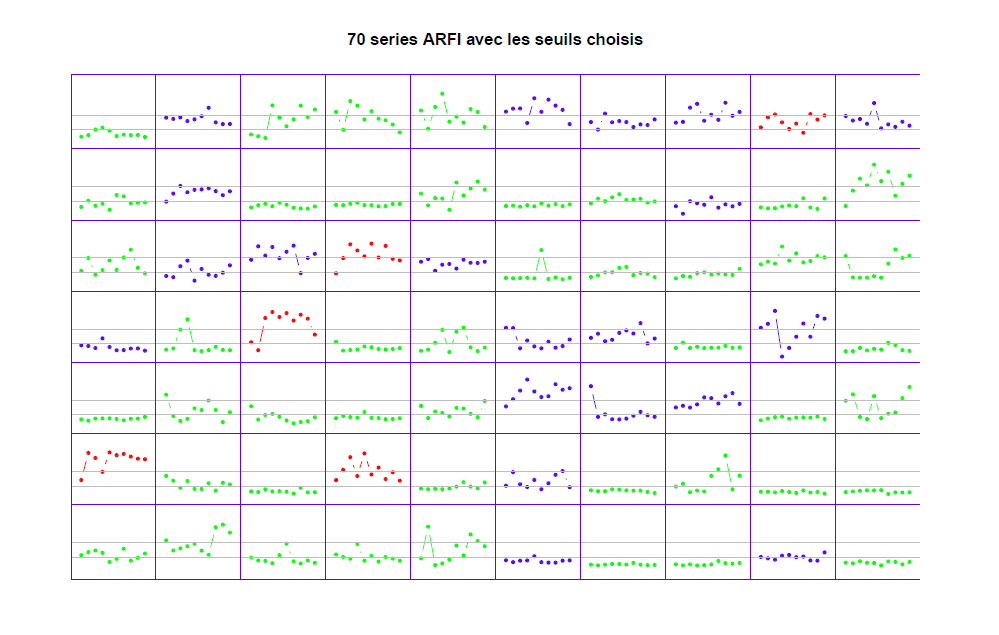
Les performances sont toutes très proches (et pas terribles ! pct BC global 64 %, 44 % pour FL=3). Une stratégie qui modélise les cibles binaires semble donner de meilleurs résultats (AUROC unitaires 0.74 et 0.8, mais AUROC modèle saturé 0.90 avec 98 variables, meilleur forward avec 68 variables, meilleur forward avec 40 variables).
La médiane sur 10 valeurs et l'IQR sur 10 valeurs semblent les meilleurs paramètres capables de prédire les classes.
Deux valeurs de la médiane pour cette médiane peuvent servir de seuils pour une classification simplifiée. L'ajout de variables biologiques améliore un peu les performances.
Mais...

Conclusions
Aucune, étude en cours !
Pourtant...
Une première proposition de deux résultats de de régression logistique binaire (avec quantifification de la fiabilité des résultats) ne convient pas aux cliniciens ayant commandé l'étude.
Une seconde série de modélisations plus avancées met en avant une analyse discriminante quadratique « rebinarisée « sur la somme des deux probabilités de classe extrêmes.
La taille des échantillons est sans doute trop faible, mais il n'est pas possible d'attendre 5 ans de plus pour avoir plus de patients (FL=3, 170 patients soit 16 %).
Donc, à suivre...
9. Distances : euclidiennes ou non euclidiennes ?
Enfin une question simple !

En métagénomique, en écologie des microbiotes bactériens/fongiques et en analyse de microbiomes où on traite des abondances [relatives] d'espèces, IL FAUT (souvent) utiliser :
des positionnements non métriques basés sur l'ordination (les rangs).
à cause de la « sémantique du double zéro » lorsque les co-absences sont non informatives.
Donc exit la norme L2 et les ACP, et bonjour
indice de dissimilarité de Bray-Curtis (qui n'est pas une distance car la propriété d'inégalité triangulaire n'est pas vérifiée) pour les comptages absolus,
à l'indice relatif de Sorensen pour les abondances relatives ;
à la distance UniFrac si on dispose d'informations phylogénétiques ;
à des analyses comme LEFSE,
au NMDS (Non-metric Multidimensional Scaling)...
C'est donc simple ?
Quitte à travailler sur des données pour espérer pourquoi ne pas recourir à la topologie et à la TDA (Topological Data Analysis) ?
cette méthode n'a pas le défaut de devoir choisir arbitrairement le nombre d'axes principaux comme en ACP,
elle n'oblige pas à projeter dans un espace à n dimensions déterminé arbitrairement par la valeur de stress comme en NMDS.
Mais... cette théorie repose sur l'homologie persistante (de la topologie algébrique ?) et principalement sur le théorème suivant

donc il faut travailler avec des CW-complexes qui sont des complexes simpliciaux à fermeture finie et topologie faible !?!
Un exemple de TDA via Yazdani

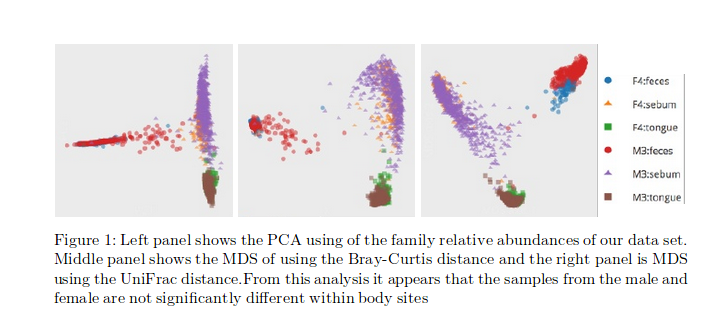
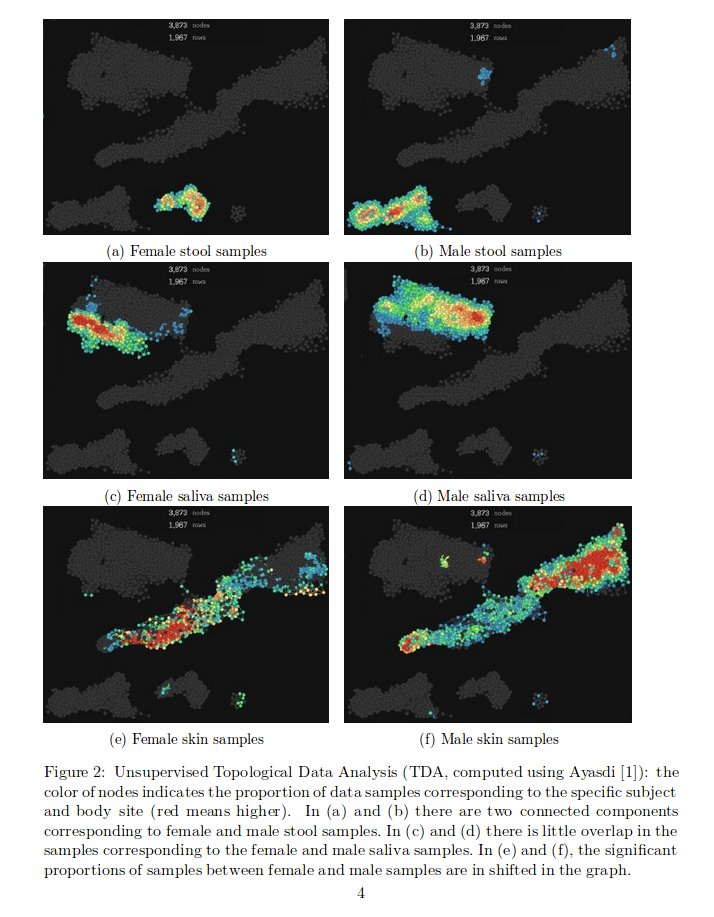
On pourra aussi consulter avec profit TDA SM2013 (B. Michel) et TDA INF556 (Oudot/Lacombe).
10. Bowtie2 : fast ou sensitive ?
Description des données
Dans le cadre d'une coopération CHU/INRA on veut analyser la composition taxonomique et fonctionnelle du microbiote intestinal (selles) de 96 patients atteints de NASH (Non Alcoholic Steatotic Hepatitis) qui est une forme avancée de la NAFLD.

Suite au séquençage de l'ADN (HiSeq3000, 2 fois 150 pb) on dispose en moyenne de 15 millions de reads pairés par échantillon, soit presque 1 To de données.

Position du problème
Après assemblage des reads en contigs, on veut regrouper les contigs en bins pour reconstruire les génomes bactériens.
Quel niveau de profondeur et quel taux de couverture faut-il utiliser ?
Questions annexes :
quel(s) logiciel(s) utiliser ? sur quelle machine ? Sanger (16s/10c/2T/70T) ; Gargantua (4s/16c/1.5T/5T+150T).
si on décide d'exécuter bowtie2, faut-il choisir l'option fast ou sensitive ?
combien de temps cela va-t-il durer ?
Dialogue de sourds (2)
[M] Je n'y comprends rien, ce n'est pas des mathématiques. [B] Ce sont des alignements donc des calculs, donc c'est des mathématiques ! [M] Je me suis renseigné, c'est du FM-index donc de la transformée de Burrows-Wheeler donc sensitive est la meilleure option. [B] ??? ! ??? Vous êtes-sûr ? [M] Non. 11. Quelques remarques pour conclure
Souvent «l'usage fait loi» et «l'expérience est reine», ce qui ne facilite pas les choix.
Il faut être très modeste car les théories mathématiques sont nombreuses et parfois ardues à mettre en oeuvre.
Reconnaître son incapacité à résoudre un problème (plutôt que « fuir/louvoyer ») permet d'avancer car cela oblige à aller chercher des compétences complémentaires.
Commencer par analyser les données présentes se révèle, au fil des années, très pertinent.
La route est souvent longue de la position du problème à une première modélisation et encore plus longue jusqu'à une solution exploitable.
Seule la collaboration interdisciplinaire permet d'y aboutir.
Pour démontrer un théorème de mathématiques, on a besoin :
- d'un papier
- d'un crayon
- un/des mathématicien(ne)s
Pour réaliser une étude en recherche clinique, il faut :
- des patients
- des secrétaires
- des infirmières
- des TEC et autres ARC
- des médecins, des cliniciens, des experts
- un/des biostatisticien(ne)s, un/des mathématicien(ne)s
... donc continuons à travailler ensemble.